2024年12月16日【守護 AI 未來:CyberArk 與 Red Hat 的聯合創新】
從開放平台到身分安全,奠定值得信任的 AI 基礎架構
- 活動地點:台北寒舍艾美 角宿廳
- 議程時間:2025/12/16 (二) 13:30-16:30
本次由 CyberArk × Red Hat 攜手,從開放平台出發,延伸到 身分安全、遠端連線與憑證管理,分享企業如何以零信任思維,讓 AI 安全落地、架構穩定運行。








從開放平台到身分安全,奠定值得信任的 AI 基礎架構
本次由 CyberArk × Red Hat 攜手,從開放平台出發,延伸到 身分安全、遠端連線與憑證管理,分享企業如何以零信任思維,讓 AI 安全落地、架構穩定運行。
促進以數據為基礎的討論部落格來源網址:Platform Engineering vs DevOps: How Different Are They?

因為這兩種模式,
它們無法支援 即時交付(real-time delivery)、平台與環境的高度複雜性,也無法滿足 工程團隊的自主權(developer autonomy)。
那麼,你是否應該徹底放下「Showback vs. Chargeback」的討論?
如果答案是「是」,那下一個問題會是:
在高度複雲、多環境、需要大幅擴展性的架構下,
答案是:FinOps。
一種更聰明、即時、彈性,且能隨著規模成長的雲財務營運方法論。
接下來,讓我們帶你深入說明。
讓我們快速看看 Showback 與 Chargeback 的核心特性有何不同。
Showback 指的是:
各團隊可以看到自己花了多少雲成本,但不需要為該花費負責。
就像收到一張雲成本的「成績單」,內容大概是:
「嘿,團隊,讓你們知道一下⋯⋯我們上個月剛支付了 12,000 美元的 AWS 費用。」
Showback 的功能就是提升「成本意識」,僅此而已。
事實上:
在最「樂觀」的情況下,就是季度結算時,如果預算爆了,
Chargeback 則是更進一步。
它不只是報告成本,而是 把成本實際回 charge(回充)給使用該資源的團隊或部門。
你可以把它想像成一封急件備忘:
「各位團隊成員,上個月你們在 AWS 的支出已達 12,000 美元,相當於我們季度預算的 60%。請檢視現行流程,評估是否有任何項目可削減或直接取消。
Chargeback 的最大優點是:會建立起「財務責任」與「成本擁有感」。
但它也可能引發副作用:
Showback vs. Chargeback:哪些做得對?哪些已經失效?
Showback 與 Chargeback 的初衷其實都很好──
它們本來的目的,是 讓團隊更清楚自己花了多少雲成本,進而逐步提升責任感與成本效率
然而,雖然這個理念至今沒有錯,但 它們的限制卻隨著多雲與雲原生架構的普及而快速放大。
如今,它們已經無法跟上企業規模、速度與複雜度的變化。
| 優點 | 缺點 |
|
|
| 優點 | 缺點 |
|
|
如果你仍然使用 Showback 或 Chargeback 來管理多雲環境,很可能正在面臨以下這些問題:
1. Showback 的結果是——什麼都沒發生
沒錯,團隊看到了數字……但接著就沒下文了。
Showback 缺乏 激勵機制、行動指引,也沒有任何改善的路線圖。
報告出了,事情卻沒有往前進。
2. Chargeback 會製造內部摩擦
當團隊收到被回 charge 的費用,但卻缺乏控制成本的權限與上下文資訊,很容易演變成:
這樣的結果完全無效,因為焦點從「合作最佳化」變成「誰該付錢」
3. 它們跟不上現代雲端的交付速度
雲端使用量早就不是靠「月報」就能掌握的時代了。
現在的雲資源是 動態、自動化、跨環境分散。
說白一點:如果問題在 30 天前就已發生,月底才看到報告根本於事無補。
4. 缺乏即時的「上下文 Context」資訊
假設你看到 EC2 使用量上週突然飆升——知道「發生了」根本不夠。
你不知道:
當你不知道 發生什麼、為什麼發生、怎麼避免再發生,
過去,企業大多把工作負載放在單一雲,或少數集中式 VM 上,那時候的成本結構簡單又容易追蹤:
但多雲環境帶來的挑戰完全不同:
傳統 Showback/Chargeback 的前提是:基礎架構線性、可控、集中、變化不大。
但多雲的世界是:快速、動態、分散、複雜、跨團隊、跨環境。
在這種架構下,唯一能跟上速度的方法就是:讓成本責任(Cost Accountability)具備「即時性(Real-
而這正是 FinOps 的價值所在。
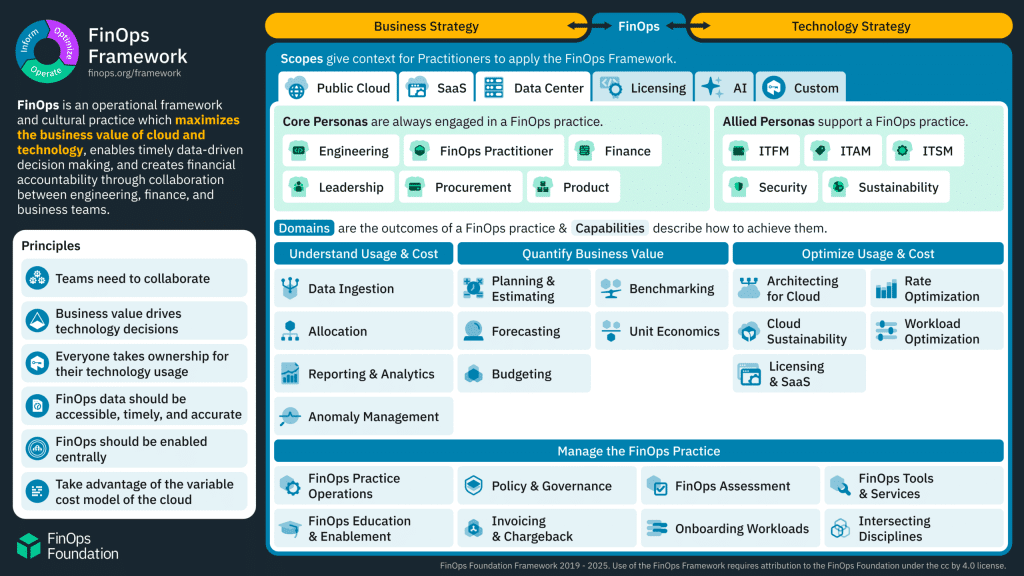
FinOps 架構 2025,由 FinOps Foundation 繪製
1. 即時(Real-time)的雲成本可視性
如果你想爬到山頂,你會選「地圖」還是「報告」?
FinOps 的本質不是「回報發生什麼事」,而是「
但像 RE:FORM RATE 這類 FinOps 工具能提供 跨所有雲端、所有環境的即時統一視圖:
這是 Showback/Chargeback 完全做不到的。
2. 共享責任(Shared Accountability)
當財務與工程部門各看各的數字版本,
這能建立責任感,而不是製造政治角力。
3. 帶著上下文採取行動(Actions with Context)
FinOps 能將成本數據直接連到工程行為:部署(deployments)
在共享資源成為常態的多雲架構中,這種上下文能讓企業從「
4. 將焦點放在改善,而不是責備(Focus on Change, Not Blame)
你一定有這種經驗:
財務或 CFO 在你後面盯著每一筆支出,彷彿你不知道成本會爆掉。但背後真正的問題不是人,而是 缺乏掌控成本的策略與工具。FinOps 的目標不是揪出誰要負責,而是:
FinOps 建立的是「能力」,而不是「懲罰」。
5. 同時擴展團隊、雲環境與流程(Scaling Teams, Clouds, Workflows)
當基礎架構不斷擴張,成本管理模式也必須同步擴張。
但 Showback/Chargeback 一遇到:
就會崩潰。FinOps 天生為擴展而設計,因為它提供:
這表示隨著規模擴大,企業能強化責任與治理,


部落格來源網址:Top Exploited CVE Patterns (And What They Reveal)

報告指出,這項攻擊手法年成長率高達 34%,主要受到自動化攻擊工具普及,
例如 Citrix NetScaler、Cisco ASA 這類作為「內外網交界」的關鍵設備,在 2025 年被發現與近 25% 的漏洞利用型入侵事件有直接關聯;

即便企業對漏洞風險的認知逐漸提高、補丁也普遍可取得,但「
雖然企業的攻擊面越來越大,但攻擊成功的方式其實高度重複——
以下是當前最常見的三大攻擊模式:
三種攻擊模式中,最危險也最具破壞性的,就是發生在邊界設備(edge-facing devices)上的遠端程式碼執行漏洞(RCE)。例如Citrix NetScaler 與 Cisco IOS XE,就曾曝露出 RCE 弱點,使攻擊者能:
這類設備通常具備高權限且位於網路與外部的交界,是企業最重要的防線。然而,它們往往:
這讓攻擊者只需要投入極低成本,就能取得極高報酬的攻擊結果。換句話說,只要邊界設備一被突破,後面的攻擊就會像推倒骨牌一樣迅速展開。
第二種常被忽略的攻擊模式,是透過繞過登入或 Session 驗證的方式直接取得存取權限。像 Atlassian Confluence 等企業常用協作工具,就曾出現讓攻擊者完全跳過登入流程、直接取得存取權限的漏洞。
這類問題並不是單一小 bug,而是能大幅放大攻擊威脅的加速器。
當這些漏洞與遠端程式碼執行(RCE)或本機權限提升(LPE)搭配使用時,攻擊者不只可以輕鬆取得初始入侵點,還能:
換言之,只要認證流程被繞過,攻擊者就能在系統裡「躲很久、動很快、抓不到」。
第三種攻擊模式,也是最令防禦者挫折的部分——攻擊者持續利用那些早已公開、甚至早已發布補丁的已知漏洞。
許多組織一次又一次地因為這些漏洞遭受攻擊——而這些弱點其實早在數個月、甚至數年前就已經被揭露並提供修補。
這種現象之所以持續,是因為:
結果就是一個緩慢但持久、難以根除的威脅環境:昨天的漏洞新聞報導,往往成為明天真正的入侵事件來源。
這不只是單純的流程雜症,而是一個明確的警訊:僅依賴「弱點分類與排程」的漏洞管理策略,正在全面失效。
如果企業沒有把組態管理和補丁衛生視為「持續性、且必須高優先處理的核心任務」,那麼再好的弱掃工具、告警平台,都只能淪為事後反應型的防禦手段,而無法真正降低風險。

當所有事情都被標示為「緊急」,那其實等於沒有任何一件真正緊急
這正是為什麼 CISA 已知被利用漏洞清單(Known Exploited Vulnerabilities, KEV)成為如此關鍵的資源。
不同於 CVSS 只會把許多漏洞標成「高風險」或「嚴重」,KEV 專注於那些已經在真實攻擊中被利用的漏洞。
它不再只是理論上的風險評分,而更像是「來自戰場的第一手情資」
對齊 KEV 的安全團隊能更果斷行動,不再迷失在「滿天 Critical」的漏洞清單中,而是把有限資源投注在確實會被
事實上,許多在 KEV 中被點名的漏洞,CVSS 分數可能不高,但因為:
而被攻擊者大量武器化。
更重要的是,KEV 改變了企業處理漏洞的方式,KEV 不只幫助企業排定優先順序,它還:
只要訂閱 KEV 更新,並將其整合至弱掃工具或資產管理平台中,
KEV 並不是用來取代 CVSS,而是一個更加貼近現實的風險校正器——它過濾掉噪音,
vRx 能將 KEV(已知被利用漏洞)情資直接轉化為可立即落地的修補行動。平台會持續自動匯入KEV 清單,並即時對照企業的實際資產清冊,不需人工比對或撰寫自製腳本,就能清楚標示:
讓修補優先順序真正與攻擊者的行為保持同步。
vRx 的核心差異:真正能落地的修補引擎
不同於傳統只能「部署補丁」的 Patch Management 工具,
vRx 具備完整的修補引擎,其中包含:
✓ 漸進式環狀部署策略
補丁以小範圍、低風險資產做為第一波測試,確認穩定後再逐步擴散至更關鍵的設備。
✓ 支援回滾機制
若補丁造成異常,可透過 Script Engine 執行 rollback 操作立即回復至前一狀態,大幅降低停機或服務中斷的風險。
此部署方式讓團隊得以快速修補、降低影響面、提升成功率。
把策略變成可執行行動:vRx 補上政策與落地之間的缺口
在多數企業中,「政策」與「實際修補行動」之間往往存在巨大落差:
這些資訊在傳統工具裡常常難以追蹤。
vRx 完整補上這個缺口,提供:
無論是內部治理、主管報告、或外部法遵稽核,企業都能確切展示:
我們何時修補、修補了哪些系統、如何修補,以及是否符合SLA。
vRx 不只是「打補丁」,而是協助企業真正做到可驗證、可證明的修補能力。

制定補丁時程不只是訂出一個基準點,而是用來強化 組織可信度、反應能力與可被稽核性 的重要依據。
一套定義清晰的 SLA,不僅代表企業「想修補」的意圖,更代表企業在高壓環境下
在以 KEV 為核心的修補模式中,SLA 的設定更必須反映出:
也就是說,SLA 不再只是內部 KPI,而是企業是否能跟上攻擊節奏的「生存指標」。
為了協助企業將這套作法制度化,下表提供了一個分層式(
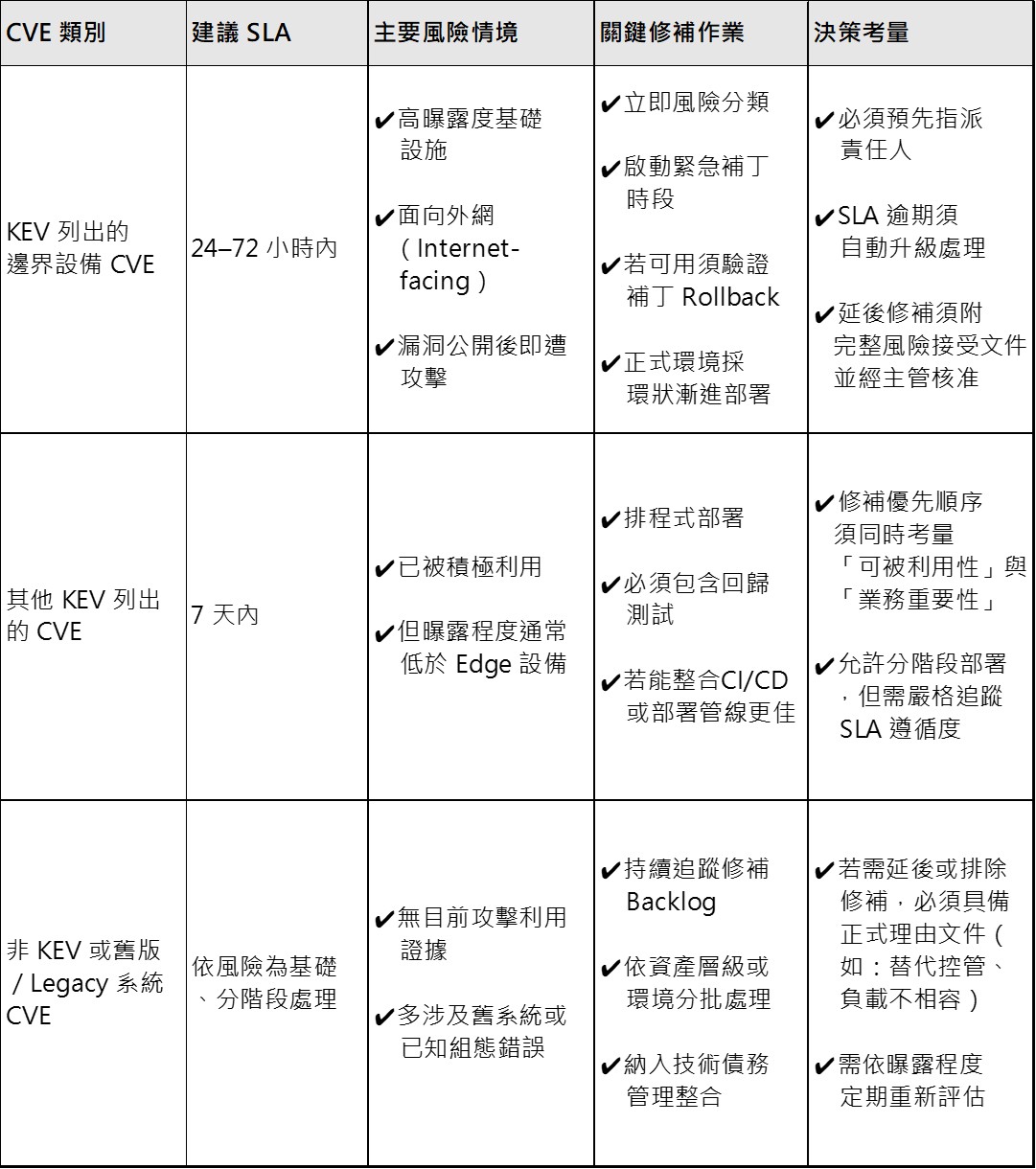
然而,僅僅設定時程還不夠。
若要讓 KEV-first 修補策略真正奏效,必須把「執行」深度融入日常營運流程中。
也就是說,政策必須透過一致的行動反覆操練,
以下是完整 Playbook 中不可或缺的要素:
一套 KEV-first 策略要真正有效,必須具備三個條件:
否則,政策只是文件上的承諾,而非能真的降低風險的能力。
但如果這套策略落地正確,它不只降低被攻擊風險,
讓資安負責人有能力提出「真正的證據」,
這是一套能被驗證、能被審核、能被信任的安全框架。
只依賴 CVSS 分數來進行漏洞分類與排程(triage),
KEV 的價值就在於,它讓安全團隊把資源聚焦在「
將 KEV 完整導入日常作業流程,企業能獲得:
商業價值非常明確:安全事件更少、事件處理時間縮短、

部落格來源網址:Complexity In Security: Why It’s Hitting Hardest at Mid-Sized Organizations


如果要用一句話總結《Bitdefender 2025 資安現況評估報告》的主軸,那就是:原本用來保護企業的資安工具
多重工具重疊、解決方案過度複雜、法遵要求彼此拼布式(
Bitdefender 對 1,200 位 IT 與資安專業人士的調查顯示,目前最主要的資安挑戰依序為:
第一名:架構與工具的複雜度(31%)
第二名:跨環境防護延伸(29%)
第三名:內部技能缺口(28%)
第四名:工具太多、難以管理(27%)
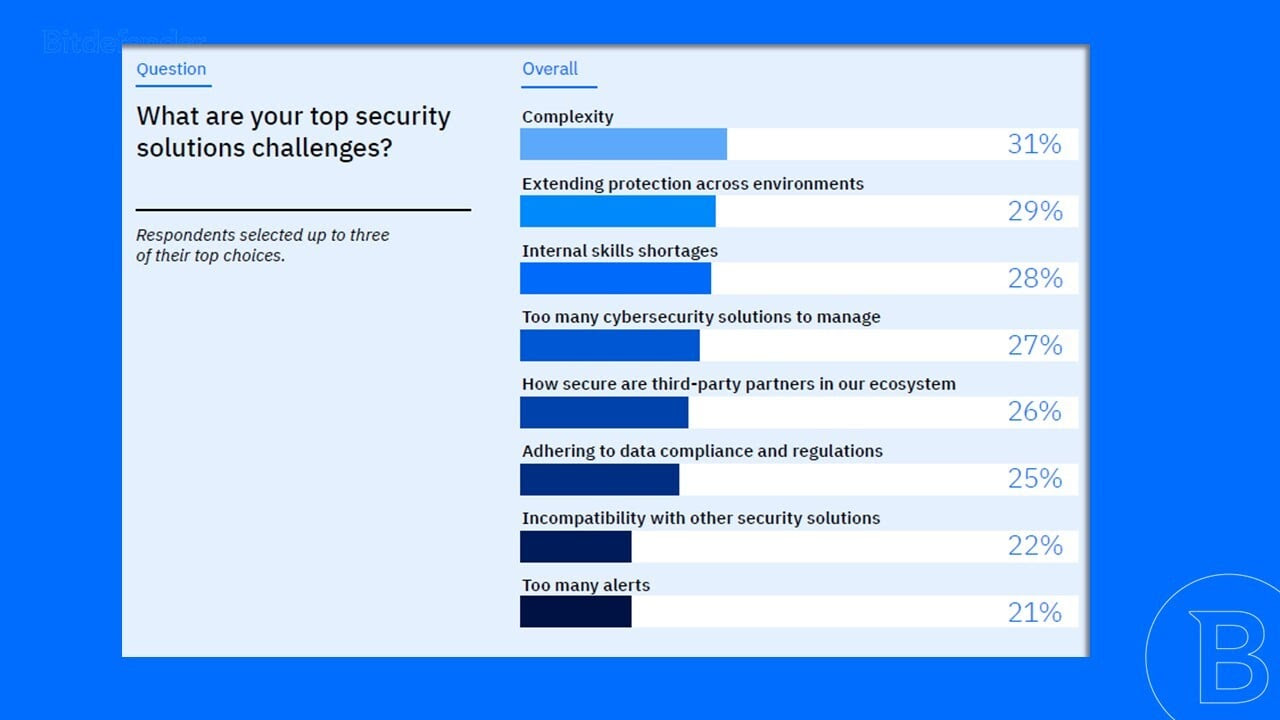
Bitdefender 網路安全服務 總監Nick Jackson 與組織密切合作,他觀察到這些複雜度問題其實彼此高度連動:
「你看著這個挑戰清單,很容易就能把它們連成一條線。技能不足,
他補充:
「法規也越來越多,工具彼此未必相容,流程也越堆越厚,
更糟的是,複雜度還衍生另一個風險:能見度不足。
高達 77% 受訪者坦言他們對自身環境缺乏足夠的洞察力。
大型企業有龐大的資安團隊與成熟架構,本來就複雜。
Bitdefender 技術解決方案總監 Martin Zugec 說得很直白:
「攻擊者不再在乎你是哪個產業,而是你用的是哪些軟體、
他點出複雜度的核心問題:
「我們總是買那個功能最多、打勾框最完整的產品。
這就是核心困境:
許多中大型企業導入了企業級的資安堆疊,
結果就是一片難以整合的工具叢林,既難優化、也不具效率。
25% 的受訪者表示,遵循 GDPR、CCPA 等法規要求本身就是主要挑戰之一。
諷刺的是:為了合規,企業往往再添購一套工具或報表系統。
看起來像增強管控,實際上卻:增加更多孤島、更破碎的流程、
每多一層複雜度,就多一層攻擊面:
而企業新增工具的速度,往往還比不上整合的速度,
好消息是:簡化並不等於功能縮水。
真正的簡化,是:
對許多企業來說,導入 MDR(託管式偵測與回應)是下一步必然選擇。MDR 不只是補人力,而是提供:
這讓複雜度不再成為壓垮團隊的重擔。
如何讓企業從複雜混亂 → 精簡有序 → 策略主導?
Nick Jackson 的建議很務實:
「你必須退一步,用策略思維問自己:我們最終想達成什麼?
Bitdefender 提供多項協助降低複雜度的關鍵工具:
唯一目標就是:減少破碎化、提升能見度,並在攻擊發生前阻斷威脅
複雜度不會自己消失。
如同調查所示,企業在面對攻擊者之前,
未來能真正提升資安韌性的企業,是那些
相關網路研討會: 從人工智慧到攻擊面:2025 年形塑資安優先事項的關鍵因素



當我剛進入職涯、在加拿大某家銀行的交易大廳工作時,
這段經歷讓我學到一件事,也成為我與客戶溝通時最核心的觀念:
但我也見過完全相反的情況:身份安全像一台調校良好的機器,
真正的轉折點在於,我意識到「商業脈絡資料(Business Context Data)」才是缺失的那塊關鍵拼圖。
它是讓身份安全與效率連結在一起的核心要素。沒有它,所有權、
但一旦具備這層脈絡資料,合規就能從周期性作業,轉變成持續、

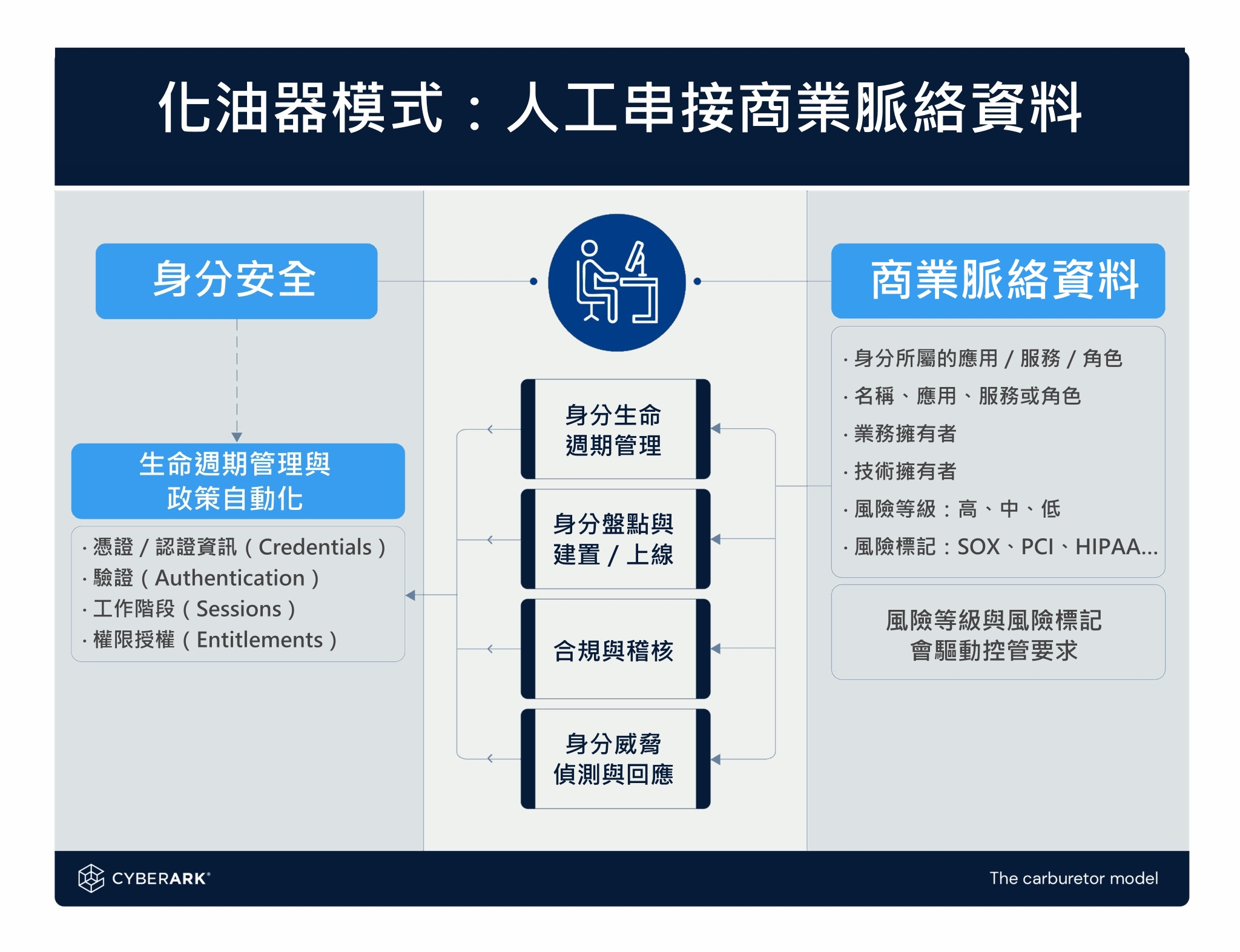
在進入科技產業之前,我曾經當過汽車技師。我調校過化油器、
這場效率競賽,推動世界從傳統化油器(想像 1985 年的 Honda Civic)走向數位化控制的電子噴射系統(例如 2025 年的 BMW 3 Series)。化油器必須靠人手反覆微調;
我在身分安全領域也看到很相似的情況。所謂的「效率」,
手動的合規流程就像化油器:被動、低效,而且高度倚賴人工調整、
自動化的控管則像現代的電子噴射系統:透過資料、感測、
那麼,究竟是什麼力量,讓企業能從手動合規邁向自動化合規?
答案就在於商業脈絡資料(Business Context Data)。
在身分安全中,商業脈絡資料就像現代引擎的感測器系統——
以稽核為例,稽核人員通常都會問一些再熟悉不過的問題:
這些問題完全合理,但大多數企業卻無法輕鬆回答。原因是:
身份相關資料往往散落在 HR 系統、應用清冊、工單系統、Log、SIEM、CMDB 等不同平台中,彼此缺乏連結。
每一次稽核都變成一場追逐「業務合理性、擁有者、權限、風險」
而商業脈絡資料能補上這道缺口。
它負責串聯各系統,並針對所有身份類型(包含人員、機器帳號、
當身分系統具備這些脈絡後,系統即可像「自動調校的引擎」一樣,
當這些要素整合在一起時,身份安全就像運轉順暢的高效能引擎——
當商業脈絡資料被納入身分管理流程時,企業便能把合規從「
我曾經看到許多客戶在把身分資料與權威資料來源(如 HR 系統、ITSM、CMDB、應用清冊)串接後,
結論其實很簡單:當你用商業脈絡資料強化身分安全,
企業不再害怕下一次稽核,而是能更早做好準備、持續維持合規、
但理解商業脈絡資料為什麼重要,只是故事的一半。
這個過程需要調校、反覆迭代,以及一連串「以資料為基礎」
在多數企業中,商業脈絡資料其實早已存在——
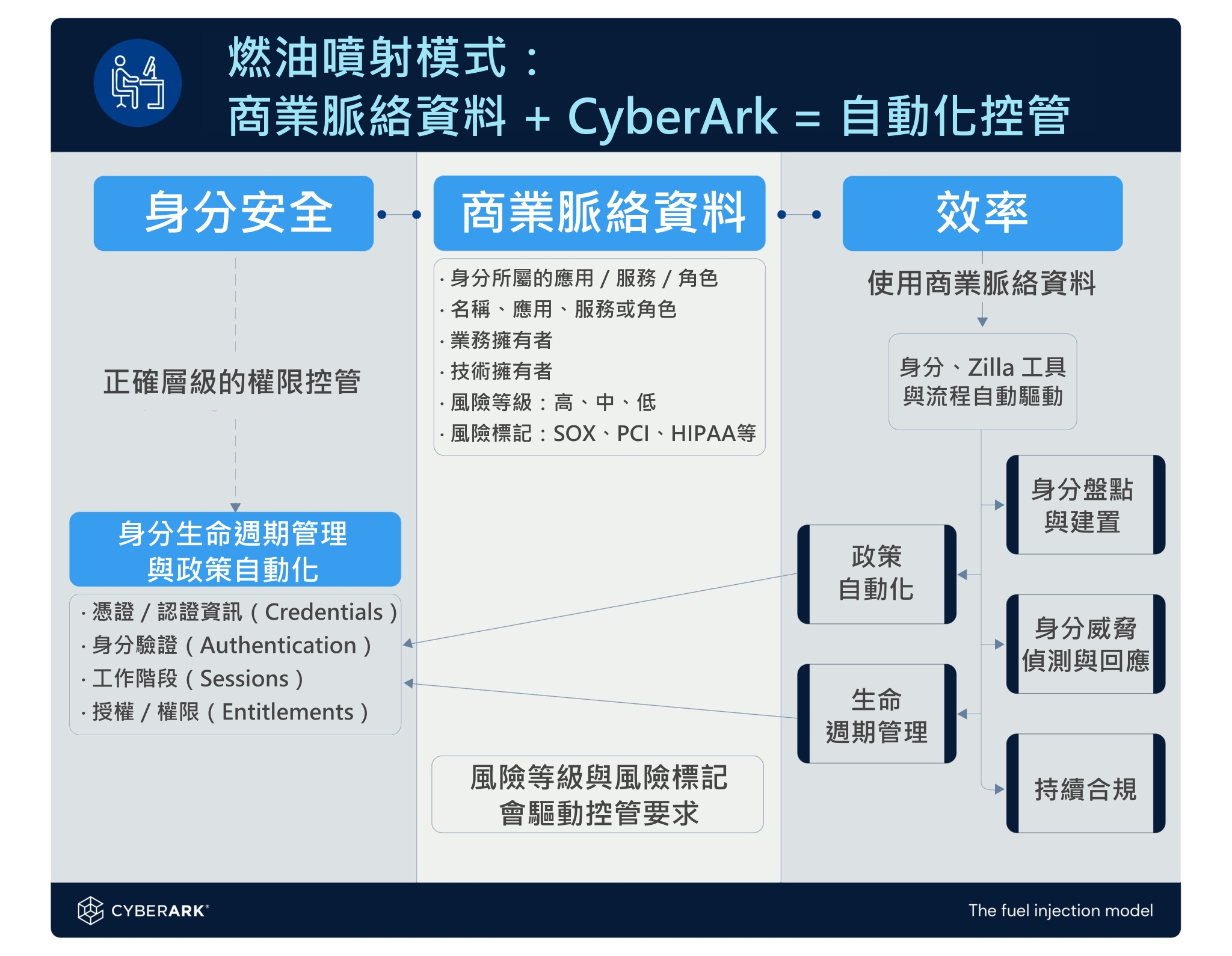
如今,像 CyberArk 這類的平台已能在整個身分管理流程中,自動同步、
要從人工流程轉向自動化,企業必須採取 全方位(holistic) 的方法,處理組織中各種不同身分類型所帶來的挑戰。
身分安全需要涵蓋多種截然不同的身分類型,
當所有身分類型都在「正確的商業脈絡」下運作時,
就像引擎需要乾淨的燃料與即時感測器才能高效運作一樣,身分安全
當企業具備正確且完整的商業脈絡資料後,「持續合規(
一切從盤點(Discovery)開始──
透過將 HR、ITSM、CMDB 與各種雲端系統同步,你能維持持續的可視性與控管能力,
脈絡化後的身分,會呈現出可預測的模式
當所有身分被正確建置(onboard)到身分治理或特權存取(
當策略與實際風險相互對齊後,團隊就能減少噪音,更有效率地落實
自動化建置讓缺口在形成前就被封閉
下一步,是在身分生成的瞬間(例如伺服器建立、應用部署、
這能確保新憑證、新帳號、新工作負載在產生的第一秒就被保護,
從反應式 → 持續式:自動化讓身分治理真正「活起來」
隨著自動化逐漸成熟,身分管理會從過去的被動、事件觸發,轉變為
換句話說,身分治理不再依賴人工追蹤,
持續合規真正落地的時刻,是當企業做到以下四件事:
當這套機制運作順暢時,安全團隊便不再受制於前期準備工作,
當這些最佳實務真正落地後,企業能立即感受到、
那些以商業脈絡資料調校身分安全的組織,
我看過許多企業從「被動式、清單驅動」的稽核模式,轉變成「
而所有成功案例背後的共同核心,就是商業脈絡資料。
它就像感測器資料一樣,推動整體的效率、韌性與信任。
當身分安全順暢運作到這個程度時,稽核不再是一種負擔,
證明這個組織確實做到它承諾的事──保護人員、保護系統、

部落格來源網址:Platform Engineering vs DevOps: How Different Are They?

DevOps 與 Platform Engineering(平臺工程)
它們是不是同一件事的兩面?或是,
事實上,兩者確實在提升應用交付流程方面有許多共通點,
你是否只要有一支開發團隊,就算是「正在做 DevOps」?
或是當你開始負責團隊使用的工具與基礎架構時,就已經成為「
更重要的是——這兩種方法各自帶來哪些關鍵優勢,
這篇文章將帶你釐清 DevOps 與平臺工程的本質,了解它們的異同,並提供實際洞見,

過去,應用開發(Development)與系統維運(
直到 2016 年,Amazon 技術長 Werner Vogels 提出那句著名的理念:「你打造它,就要負責運行它(You build it, you run it)」,正式揭開 DevOps 思維的時代。
自此之後,DevOps 的概念被廣泛採用:開發與運維團隊密切合作,透過持續整合(
自動化流程大幅減少人為錯誤,讓軟體交付更快速、更穩定、
然而,DevOps 不只是技術或工具的集合,而是一種文化與思維的轉變。
它倡導團隊間的透明協作、共享責任與持續學習,
隨著 DevOps 成為業界主流,
除了要熟悉各式雲端工具與自動化技術外,
這樣的要求導致開發人員長期面臨資訊過載與高壓負荷,
儘管挑戰不少,DevOps 的價值仍十分明確,它能帶來以下四大效益:
1. 更快的產品上市時間
透過 CI/CD 流程整合,DevOps 能加速開發與部署,使產品能更快回應市場需求。
2. 自動化提升效率
自動化測試、部署與監控等重複性工作,減少人為錯誤,
3. 跨團隊協作更順暢
DevOps 打破開發與運維的隔閡,推動透明與高效率的協作文化。
4. 資源最佳化與成本下降
自動化與流程優化能降低人工作業成本,讓資源運用更精準,
從 2000 到 2020 年的開發者「認知負荷(Cognitive Load)」呈現持續上升趨勢,DevOps 雖提升效率,但也讓團隊面臨越來越高的技術與資訊壓力。
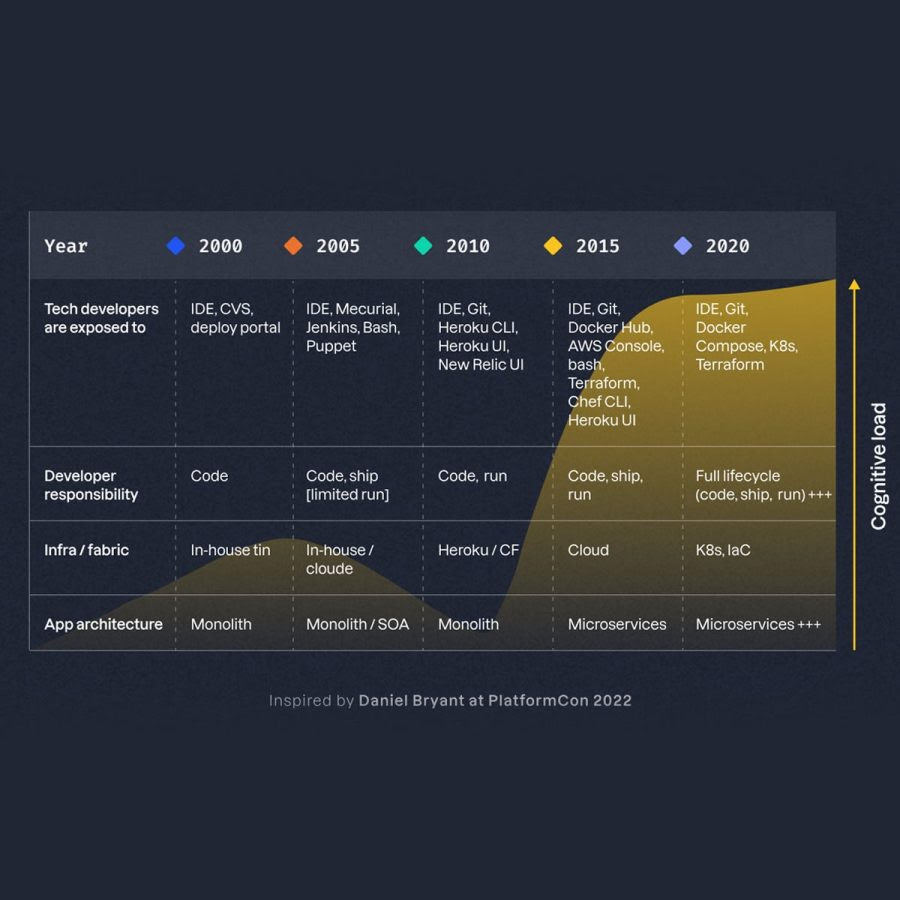
表格:認知負荷趨勢(2000-2020)
平臺工程專注於設計、打造與維護自助式(Self-
平臺工程透過簡化 CI/CD、自動化部署與全程監控,
簡單比喻:
如果應用開發像經營一間餐廳,開發人員就是廚師;
他們維持一個「乾淨、透明、高效」的廚房環境,
最終目標很明確——讓每個人都能專注在自己最擅長的領域,
根據多份業界報告與研究,平臺工程已為企業帶來可量化的績效改善
在 Puppet 發布的《State of Platform Engineering 2023 調查報告》中,高達 94% 的受訪者認為平臺工程讓他們更能發揮 DevOps 的效益。
其中包括:
多數企業一致認為:平臺工程讓開發者「工作更輕鬆、交付更穩定、
除了上述效益外,平臺工程還能:
然而,導入平臺工程並非一蹴可幾。
一個有效的平臺工程方案,必須被視為「產品(Product)」
這意味著:平台需要根據「使用者需求」——
如果平臺工程團隊沒有與 DevOps 團隊緊密合作,或未納入實際開發者的回饋,就可能導致:
此外,平台的運作也需要長期的維運資源與專業支持。
閱讀更多: 何謂平臺工程?您是否需要它?

Gartner
DevOps 是一種文化與方法論,強調開發與運維團隊的緊密協作,
相對地,平臺工程的重心則在於設計與維護一個自助式的開發平臺,
藉由標準化的流程與工具組合,協助開發者減輕認知負荷(
DevOps 與 Platform Engineering 的簡易比較
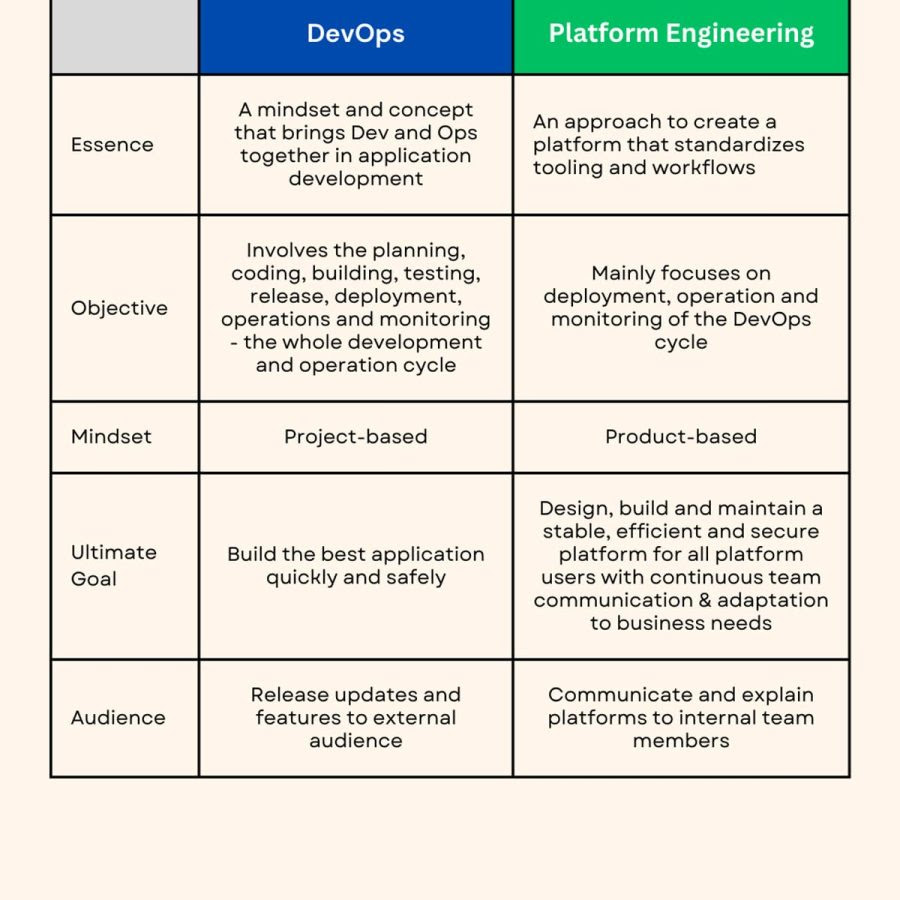
在應用開發與交付的整體架構中,DevOps 與 Platform Engineering 既相輔相成,又各自扮演不同的關鍵角色。
DevOps:
DevOps 是一種著重於「應用開發與交付流程」的思維與實踐模式。
它涵蓋從規劃、撰碼、測試、發布、部署到監控的完整生命週期。
透過持續整合(CI)、持續交付(CD)與自動化工具,
Platform Engineering:
平臺工程則著重於設計、建置與維護應用所依賴的基礎平臺。
平臺工程師的核心任務是確保整個開發平臺的安全性、穩定性與效率
DevOps 的目標:
DevOps 旨在運用自動化的力量來簡化並加速應用交付流程,打破開發(
成功的 DevOps 團隊,能夠快速回應市場變化,穩定且無誤地交付高品質應用,
Platform Engineering 的目標:
平臺工程師的日常任務,則圍繞於了解與整合各團隊的實際需求,
平臺工程是一項持續性工作,需要快速回應業務變化與技術挑戰,
最終目標是為技術與業務團隊提供穩定、可擴展的基礎環境,
DevOps:
DevOps 團隊以「專案導向(Project-Oriented)」為主,
然而,隨著工具鏈與基礎架構的快速膨脹,DevOps 團隊除了開發與維運外,還必須兼顧安全、合規與文件維護等責任,
Platform Engineering:
平臺工程師則採取「產品導向(Product-
他們會傾聽開發、運維與業務團隊的挑戰與需求,
此外,平臺工程師也負責在組織內推動思維轉型(Mindset Shift),說明平台價值、提升跨團隊協作。
可以說,平臺工程師是應用交付流程中最關鍵的「協調者」與「
要比較 DevOps 與 Platform Engineering 誰「更好」,其實就像在比橘子與紅蘿蔔——兩者本質不同,
在核心理念上,DevOps 與 Platform Engineering 都是為了打造更高效、更穩定的應用交付體驗。
DevOps 的重點在於加速應用開發與部署,而 Platform Engineering 則扮演強化與穩定現有 DevOps 環境的基礎引擎。
它提供一個穩固的平台架構,
然而,若真正了解 何謂平臺工程 的運作原理,你也會發現——並
那麼,該如何判斷「你的企業是否需要它」呢?
在跳上平臺工程列車」之前,
根據 RE:FORM 的實務經驗,當企業具備以下條件時,導入平臺工程最能發揮成效:
想知道平臺工程如何幫助你優化應用交付效能嗎?
RE:FORM 提供 All-in-One 的 Platform Engineering(平臺工程)解決方案,結合智慧化、
無論你目前的 DevOps 成熟度為何,RE:FORM DEPLOY 都能幫助你加速、簡化、並穩定整個交付旅程。
 立即聯絡我們
立即聯絡我們 




部落格來源網址:How Modern Vulnerability Management Keeps Up with 40,000+ CVEs


隨著漏洞揭露數量持續暴增,「漏洞管理(
僅在 2024 年,就有超過 40,000 個 CVE(Common Vulnerabilities and Exposures) 被公布,比 2023 年的 28,961 個再度大幅成長。
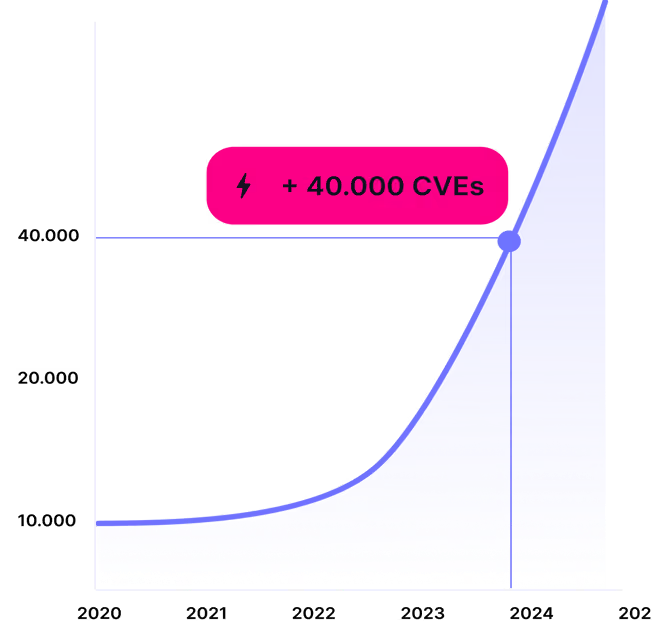
傳統的漏洞掃描機制早已不足以因應這樣的速度。
現代企業需要的是結合 持續監控(Continuous Monitoring)、漏洞掃描(Vulnerability Scanning) 與 風險導向優先排序(Risk-Based Prioritization)的新一代漏洞管理架構。
因為駭客往往能在幾天內就利用新漏洞展開攻擊。
只有持續監控能及時偵測新風險,
出現的漏洞,而基於風險的優先級排序則決定應修復哪些漏洞。
如今,新漏洞每 17 分鐘就會出現一次 ,而攻擊者只需 5 天 就能將漏洞武器化、實際利用。沒有持續監控的防禦機制,就代表在兩次掃描之間的數週或數月內,
現代化的漏洞管理平台能針對地端與雲端環境進行近乎即時的動態評
讓「從發現漏洞到完成修補」之間的落差大幅縮短。
但光有掃描還不夠,企業必須導入「風險導向優先排序」
事實上, 僅約 2%的暴露點會直接危及關鍵資產,75%的漏洞實為死胡同。
現代漏洞管理工具更能分析攻擊路徑(Attack Path),將漏洞結果與設定錯誤(
這種整合視角正是有效漏洞管理的關鍵。
想要在大規模環境中落實持續監控,自動化(
手動掃描已無法跟上現代基礎架構的速度。
雲端部署、微服務(Microservices)、
這些自動化流程(Automated Pipelines)是現代漏洞管理的中樞,
能將偵測結果直接導入工單系統,追蹤修補進度並建立稽核紀錄。透過 「掃描+持續監控+風險導向優先排序」 的組合,資安團隊能專注於最有影響力的漏洞,並以自動化的節奏維
研究指出,自動化至關重要,
現代攻擊者不僅利用漏洞,還會結合錯誤設定、
因此,資安領導者逐漸採用 CTEM(Continuous Threat Exposure Management,持續威脅暴露管理)框架,
範疇定義(Scoping)→ 發現(Discovery)→ 優先排序(Prioritization)→ 驗證(Validation)→ 動員(Mobilization)。
這套流程強調的不只是掃描,而是持續監控與風險驗證。
藉由結合漏洞掃描與組態分析,
最終成果是建立一個「橫跨掃描、監控與優先排序」
為有效實施持續監控與漏洞管理,請考慮以下實務做法:
1. 完整資產盤點(Asset Inventory)
你無法修補你看不到的風險。
透過自動化發現與持續監控整合,
2.採用持續掃描(Continuous Scanning)
從季度掃描轉向即時、持續性的評估。
讓系統在新資產上線時自動觸發掃描,成為漏洞管理的基礎。
3. 導入風險導向優先排序(Risk-Based Prioritization)
結合 CVSS、EPSS、CISA KEV 等指標,再依資產關鍵性與可利用性動態排序,聚焦真正威脅。
4. 自動化工作流程(Automate Workflows)
整合掃描工具與工單系統,讓高風險漏洞自動派單與修補。
自動化讓團隊能即時反應,保持修補節奏不間斷。
5. 納入暴露面管理(Exposure Management)
別只看軟體漏洞,也要檢視組態錯誤與身分風險。
暴露面管理能為風險排序提供更完整脈絡,確保防護面面俱到。
6. 教育用戶並衡量成效(Awareness & Metrics)
人為疏失仍是主要攻擊途徑。
持續的資安意識教育與量化指標(如平均修補時間 MTTR)能幫助組織優化整體防禦流程。
季度掃描的時代已然終結。在每年數萬個新漏洞、
但「發現」並不等於「防護」。
風險導向優先排序(Risk-Based Prioritization)是將無數漏洞資料轉化為可執行行
現代漏洞管理講求三者的協作:
唯有三者相互結合,企業才能真正控制風險洪流。
透過自動化與脈絡化分析,漏洞管理不再只是「例行打勾」的項目,
在這個每 17 分鐘就有新漏洞誕生的世界裡,只有「持續防護(

部落格來源網址:Why Hypervisors Are the New-ish Ransomware Target


資安最大的挑戰之一,就是威脅不停在換招。
這篇文章的目的,就是把最新的攻擊趨勢攤開來講,
現在的勒索攻擊團體(Ransomware Groups)刻意維持低調,避免被執法單位盯上或被制裁。
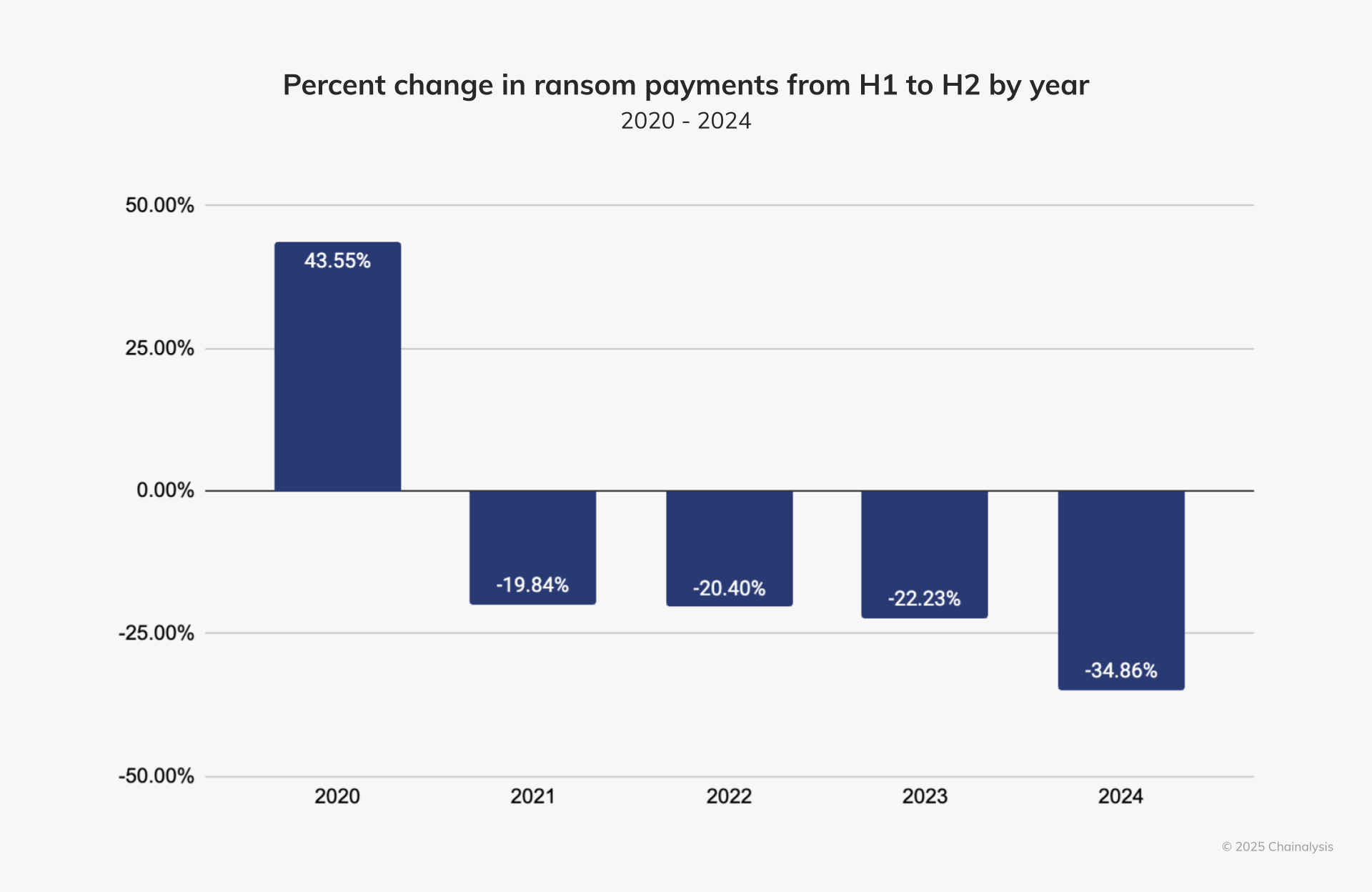
傳統「加密資料檔案」的勒索模式,從 2022 年開始一路在下滑,現在仍在下降。但這並不是好消息。相反地,
這個策略轉向,某種程度也解釋了一個很令人擔心的現象:
我們的推測是:攻擊者開始打關鍵基礎架構、動作越來越隱蔽,
在此期間,根據 Chainalysis 數據顯示,勒索軟體支付金額亦呈現下降趨勢。我們當然希望,
攻擊 Hypervisor 的目標,並不是去加密 Hypervisor 自己的核心系統,而是鎖死整台 Hypervisor 上跑的所有虛擬機(VM)。
因為現在企業內部的大部分 IT 基礎環境都已經虛擬化了,只要 Hypervisor 被入侵,攻擊者基本上就拿到整個公司的命脈,等於一拳打在中樞,
攻擊端點(工作站、伺服器本機)跟攻擊 Hypervisor,最大的差別在於「攻擊範圍」與「
傳統勒索打端點時,通常做的事是:
但攻擊 Hypervisor 是完全不同的打法。它直接下手在虛擬化管理層本身:入侵 Hypervisor 後,攻擊者會把上面所有 VM 的虛擬磁碟檔案整批加密。結果就是——這些 VM 直接無法開機。你的應用系統、後端服務、關鍵伺服器,
這不只是「資料不可讀」的問題,而是「整個 IT 環境被打到完全不能運作」。本質上,這是一種從「影響單一機器」
攻擊 Hypervisor 的目標,並不是去加密 Hypervisor 自己的核心系統,而是鎖死整台 Hypervisor 上跑的所有虛擬機(VM)。
因為現在企業內部的大部分 IT 基礎環境都已經虛擬化了,只要 Hypervisor 被入侵,攻擊者基本上就拿到整個公司的命脈,等於一拳打在中樞,
攻擊端點(工作站、伺服器本機)跟攻擊 Hypervisor,最大的差別在於「攻擊範圍」與「
傳統勒索打端點時,通常做的事是:
但攻擊 Hypervisor 是完全不同的打法。它直接下手在虛擬化管理層本身:入侵 Hypervisor 後,攻擊者會把上面所有 VM 的虛擬磁碟檔案整批加密。結果就是——這些 VM 直接無法開機。你的應用系統、後端服務、關鍵伺服器,
這不只是「資料不可讀」的問題,而是「整個 IT 環境被打到完全不能運作」。本質上,這是一種從「影響單一機器」
勒索組織基本上是很務實的犯罪集團。他們做每一步,都是算過投報率(ROI)。也就是說,他們不是迷信媒體炒作的「AI 超級駭客神技」,而是選擇最有效、最賺、風險最低的路徑。例如:打邊界設備(edge devices)、打關鍵基礎架構(像虛擬化平台),而不是炫技。
當我們觀察到多個勒索即服務(RaaS, Ransomware-as-a-Service)集團同時開始用一樣的手法,幾乎可以確定:這不是巧合,而是這條路真的「好用又好收」。
讓攻擊者更容易鎖定 Hypervisor 的一個關鍵因素,是他們開始大量使用支援多平台編譯的現代語言,
這些語言讓他們可以用同一套原始碼,
過去,勒索程式往往得為單一平台客製(例如只針對 Windows)。現在,攻擊者只要寫一個 Golang 或 Rust 的「加密器(encryptor)」,就能同時打到:
針對虛擬化管理程式的關鍵驅動因素,在於運用現代跨平台語言,
這表示什麼?表示他們可以一套武器吃多種環境,擴張非常快,
勒索集團的生意模式,說白了就是「勒索+談判」。
打 Hypervisor 對他們有幾個超現實的優勢:
對攻擊者來說,低噪音代表什麼?代表壓力被「鎖在 IT 團隊的房間裡」,不一定馬上變成公關危機或法遵問題。
這一點,對受害企業(尤其是關鍵基礎設施、受法規約束的單位)
攻擊 Hypervisor 還有一個讓勒索集團超愛的優勢:他們提供的解密工具,
原因在於流程設計本身。攻擊者在加密前,會先把所有 VM 都正常 shutdown。這代表:
結果是:加密幾乎可以做到「接近完美」。
那解密呢?因為被加的是 VM 磁碟檔,而不是散在各台端點的各種資料夾,所以事後只要在 Hypervisor 上跑一次解密工具,就有機會整批把虛擬機復原,
這種「高成功率的解密承諾」,反過來會提高受害公司「
在很多企業裡,Infra / 系統管理團隊的 KPI 是「穩定營運、不中斷」,不是「資安零風險」。結果往往是:
最典型的案例之一是 CVE-2024-37085。這個弱點被像 Black Basta、Akira 這類勒索集團實際利用過。問題點在於:
而且重點是:Hypervisor 不會去檢查這個群組是不是合法的、SID(安全識別碼)
也就是說,一個已經摸進內網的攻擊者,只要在 AD 裡新建一個群組、或把一個群組改名成「ESX Admins」,再把自己帳號丟進去,他就秒變整個 ESXi 叢集的超級管理員。這是設計層級的致命洞。
另一個大家應該都聽過的例子是 ESXiArgs 勒索行動。該攻擊大規模利用 OpenSLP 服務的已知弱點(CVE-2021-21974)拿下成千上萬台 ESXi 主機的控制權。問題在於,修補程式其實早就釋出快兩年了,
還有一個現實問題:很多 Hypervisor 本身官方並不支援在宿主層安裝 EDR / XDR Agent。廠商往往建議「你在每台 VM 裡面裝安全代理就好」。但如前面所說,Hypervisor 攻擊手法是先把 VM 關機再加密磁碟,VM 裡的 EDR 完全派不上用場。等於傳統端點型防護直接被繞過。
最後一個殘酷的現實:攻擊 Hypervisor 的副作用,是把全部壓力直接丟在內部最小的一個團隊上——系統/
這不是像傳統勒索那樣,整家公司幾千個使用者報案說「
相反地,Hypervisor 攻擊的後果,瞬間集中在一小群關鍵技術人員身上:
換句話說,攻擊者是故意「把人關進小房間裡壓著談」,
多個勒索即服務(RaaS)集團已經證實會直接鎖 Hypervisor。對這些成熟的勒索營運團隊來說,
CACTUS 是一個很典型的「多平台勒索」案例。
這個團隊在同一波攻擊裡,同時針對 Hyper-V 跟 ESXi;
攻擊流程非常工整:他們會把客製工具複製到 ESXi 主機上,給它執行權限,然後用指定參數啟動。指令可以很細,
RedCurl 通常被描述成「企業間諜型」攻擊者,但有一個相當可信的推測是:
我們觀察到一個很有意思的手法:RedCurl 在執行攻擊時,會刻意「不加密」負責網路路由/連線的那些關鍵 VM。也就是說,內網網路還會留著、基礎連線還可以用,
我們也看到其他成熟勒索團體或其後繼者延續同樣套路:
要特別說明的是:RaaS 團體本身很常解散、改名、或被法辦。但武器(像是專門針對 Hypervisor 的加密器)、攻擊手法 SOP、談判腳本,會被轉賣或沿用。也就是說,就算某個名字「
最基本的底線,真的就是把 Hypervisor 和它的管理軟體維持在最新可用版本,該打的補丁要打。
接下來幾個是不能退讓的底線:
同時,企業也必須針對「Hypervisor 遭攻擊」情境,事先寫好、練過的事件應變流程(Incident Response Plan)。
這份計畫至少要包含:
說清楚白話一點:不要等整個虛擬化叢集被鎖死後,才開始問「

部落格文章出處:The invisible threat: Machine identity sprawl and expired certificates


一個「未受管控」的機器身分,就足以讓整個企業停擺!
只要一個未受管控的機器身分——無論是一張TLS憑證、
沒有人能倖免。事實上,過去 24 個月有 83% 的企業組織 在過去24個月內曾發生過憑證相關的中斷事件。即使是科技巨頭,
問題的根源在於:
而一旦缺乏管控,這些「無主機器身分」將成為一種無聲卻致命的中

沒有機器身分,系統根本無法運作。
這些身分是讓應用程式、AI 代理 、伺服器、機器人與IoT裝置能安全交換資料的信任基礎。
但當數位生態系爆炸性成長時,這些身份的管理變得愈來愈複雜,
1. 數量爆炸
成千上萬、甚至百萬等級的識別(TLS 憑證、SSH 金鑰、程式碼簽章憑證、雲端存取金鑰與 API 機密)如今在應用程式、API、伺服器與工作負載中悄然擴散,
隨著 AI 代理與自動化程式的普及,每一個自動流程都需要新的金鑰、
2. 生命週期加速
數位憑證的使用壽命正在縮短。由於新的安全命令與瀏覽器規範,
94% 的資安主管擔心其組織尚未準備好面對更短的憑證壽命——
3. 管理複雜度攀升
從金鑰格式到加密標準再到 後量子密碼學(PQC),
結果是:機器身份爆炸(Machine Identity Sprawl)已成為營運中斷、
大多數企業組織根本不知道自己擁有多少機器身分,
在沒有中央可視性的情況下,
重複因憑證過期而造成的連續中斷不僅消耗團隊士氣,
對於資安長(CISO)來說,這會成為一個極為棘手的營運問題。
隨著憑證的有效期限持續縮短,而企業組織同時倚賴越來越多樣化的 SSH 金鑰、機密憑證與程式碼簽章證書時,
首先,組織必須建立明確的政策及全組織一致的憑証管理標準。清楚
接著:朝自動化邁進。隨著憑證有效期限日益縮短且環境日益複雜,
以下是自動化憑證生命週期管理如何消除盲點並協助資安團隊專注於

過去被視為「後勤 IT 問題」的憑証管理,如今已成為董事會層級的優先議題。
機器身份安全不僅關乎系統穩定,更直接影響企業韌性、
透過主動式管理與自動化治理,
結論很明確:別讓看不見的複雜度擾亂你的未來。
自動化、以政策為導向的機器身分管理——涵蓋憑證、SSH 金鑰、程式碼簽章憑證與機密資訊,並具備嚴格治理——
CyberArk Certificate Manager(SaaS/Self-Hosted)
讓您以自動化方式安全掌控所有機器身分:
別再讓 Excel 當你的防線。
以 CyberArk Certificate Manager 讓憑證管理邁向零中斷、零人錯、零罰則的新世代。
Florin Lazurca 是 CyberArk 的產品行銷總監。



