資訊悅報 Vol.48|REFORM DEPLOY: 告別繁瑣 Ops 申請單,開發者如何 20 分鐘完成 Web 應用部署?
部落格來源:How to Deploy Web Application in minutes with RE:FORM
 RE:FORM DEPLOY:數分鐘內完成 Web 應用部署的簡潔之道
RE:FORM DEPLOY:數分鐘內完成 Web 應用部署的簡潔之道
在 RE:FORM,我們深信簡約的力量,特別是在 DevOps 和應用程式交付方面。
您的團隊是否仍然需要透過申請單請 Ops 團隊協助建立伺服器、設定 Firewall 或配置環境?又或者,
開發人員已經花費太多寶貴時間在冗長會議中,
現在是改變的時候了。企業需要更快速、更智慧的方法來簡化 DevOps 工作流程,並提升軟體、Web 與行動應用的交付效率。在 RE:FORM,我們的目標是讓應用交付流程更順暢、
RE:FORM DEPLOY:一款智慧型持續部署自動化工具
如果企業級應用部署不再需要數週甚至數月,
以下將透過一個簡單範例進行示範:本文將帶您了解如何在 20 分鐘內完成簡易 Web Application 的部署。這包含建立伺服器、配置環境,以及完成程式部署,
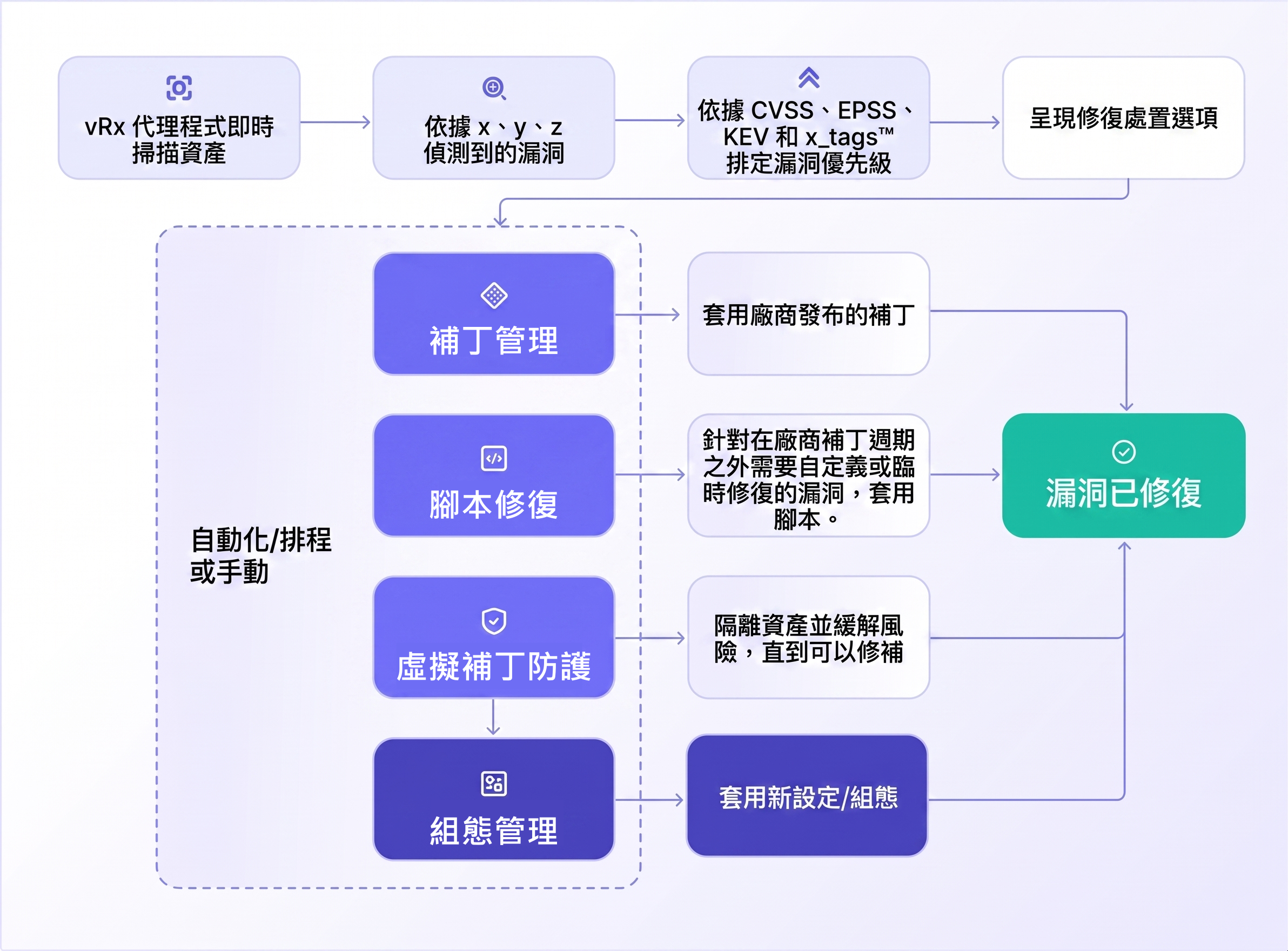
RE:FORM DEPLOY是如何運作的?
DEPLOY 提供 DevOps 與 Platform Engineering 團隊一個自助式集中管理入口,支援多種部署設定與雲端環境,
本文將展示 RE:FORM DEPLOY 的多項功能,包括元件建立(例如 S3 Bucket、API、UI 等)、由 HashiCorp Vault 驅動的 Vault Dynamic Secrets 功能,以及與 AWS、Kubernetes 等平台整合的 Everything-as-Code 能力。
使用 RE:FORM DEPLOY 在數分鐘內完成 Web Application 部署|逐步操作流程
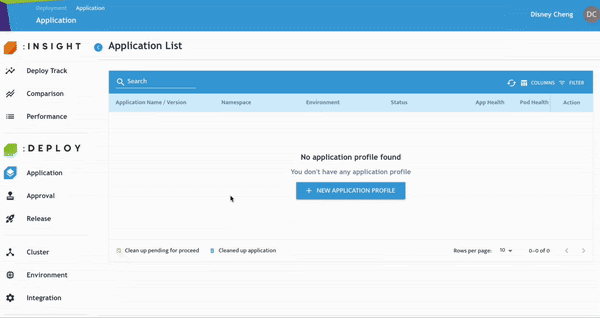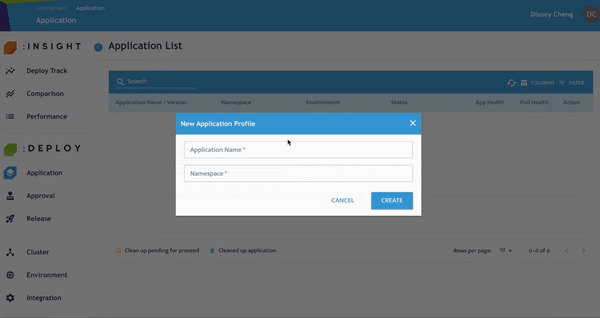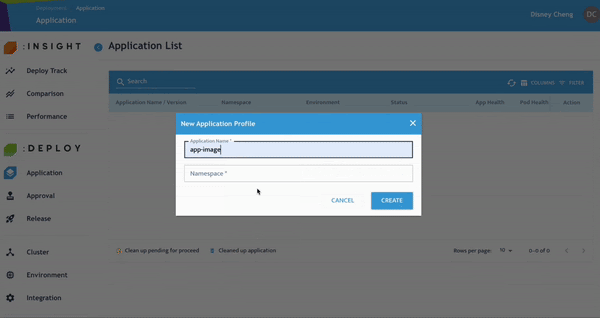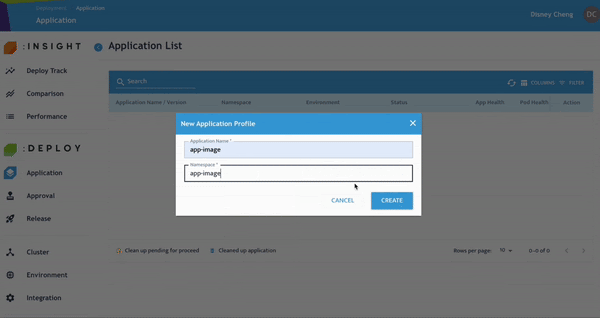
步驟 1:建立新的應用程式設定檔
- 點選 Application,新增新的 Application Profile。輸入的 Namespace 將自動建立對應的 Kubernetes Namespace。
- 點選 Application 名稱即可編輯環境,例如 Pre-production、Production、
Staging 等。完成後點選 Confirm。 - 需注意的是,
基礎架構與服務元件會依據客戶需求與產業標準事先定義。 企業可依照自身治理需求進行高度客製化,以兼顧彈性與安全性。
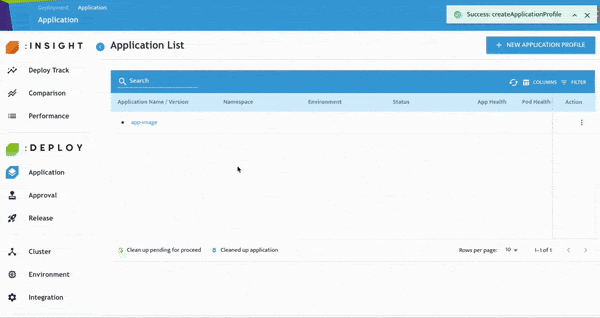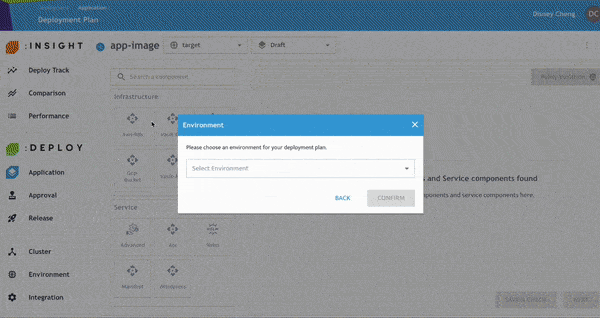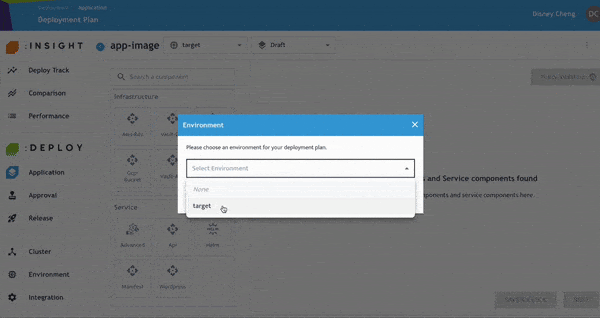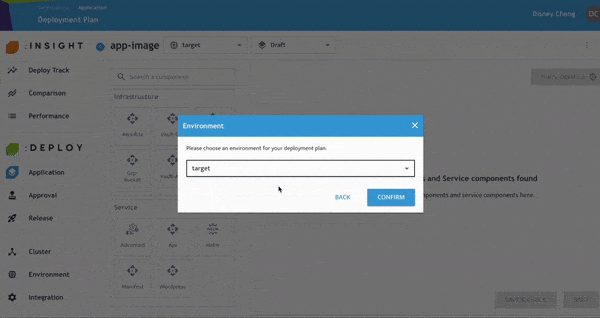
在台灣企業實務情境中,這類預先定義的標準化部署流程,
步驟 2:設定 S3 Bucket 元件
在傳統 S3 Bucket 建置流程中,通常需要由基礎架構團隊提供 Access Key 給開發人員。然而,密鑰管理可能帶來風險,例如 Hardcoded Secrets 或 Secret Leakage。
為了降低這類風險,我們的元件整合了由 HashiCorp Vault 驅動的自動化 Secret 管理流程。因此,使用者只需:
- 將 AS-S3-VSO 元件拖曳至畫布中,並新增名稱。
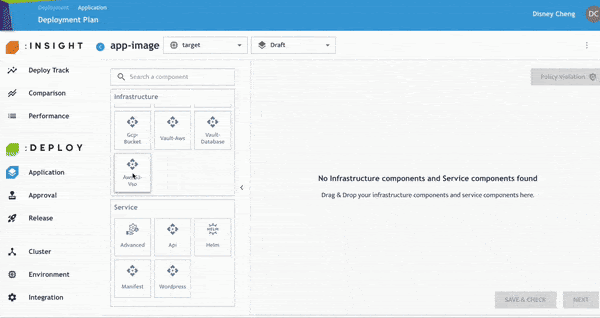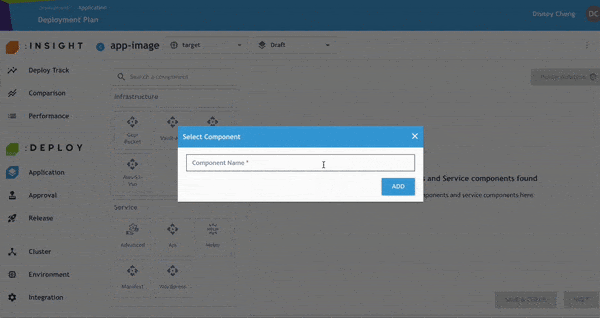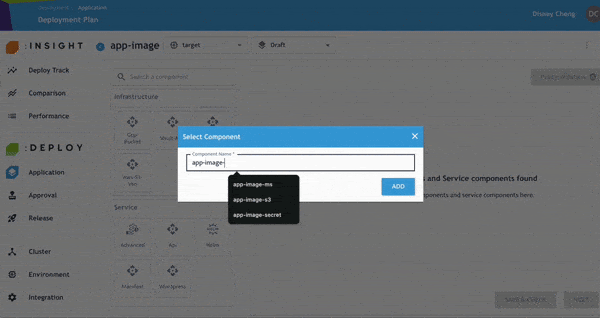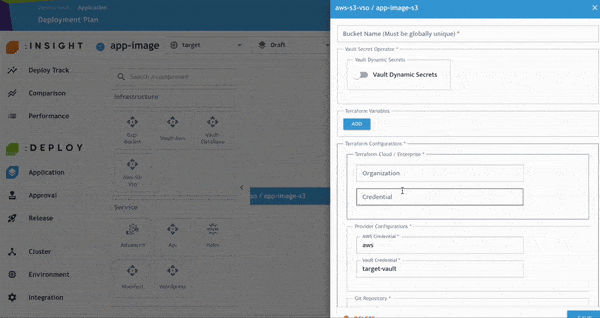
- 啟用「Vault Dynamic Secrets」功能,接著指定哪個服務將存取該 Secret。
- 如有需要,可調整 Priority。完成後點選 Save。

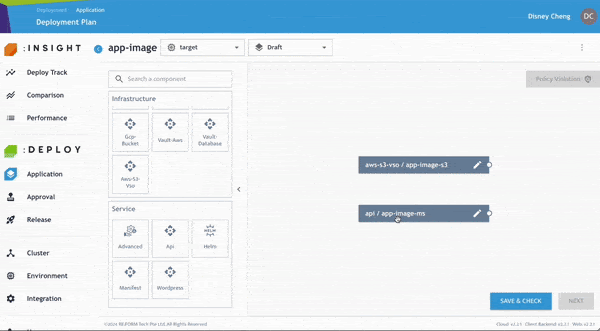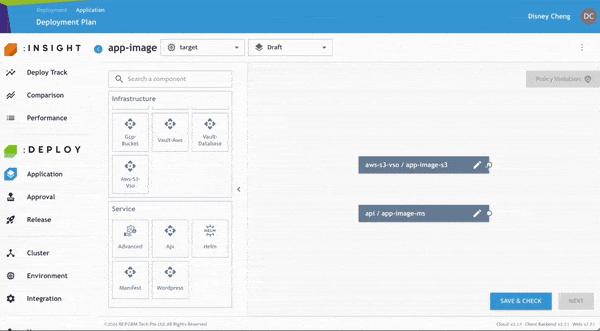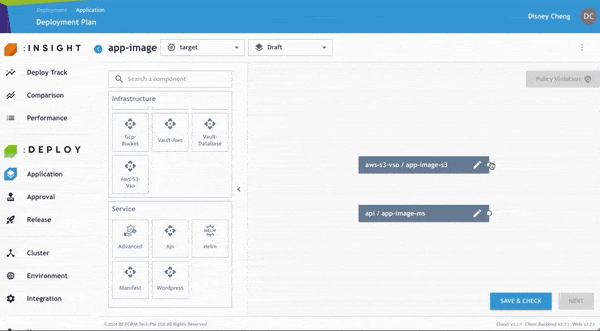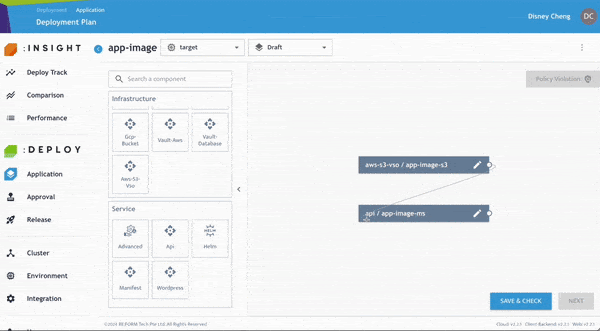
儲存後,即可在畫布上看到已建立的元件。
步驟 3:新增 API Service 元件
- 將 API Service 元件拖曳至畫布中。
- 輸入元件名稱,該名稱必須與「Secret Consumer Service Name」欄位中的值一致。
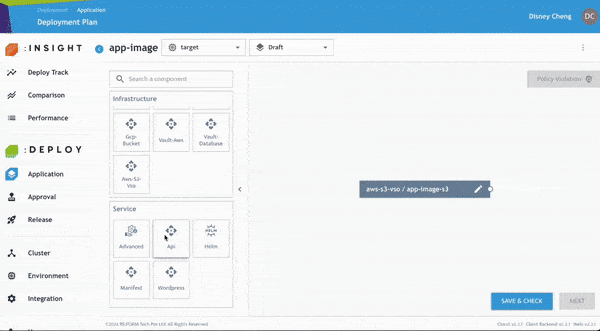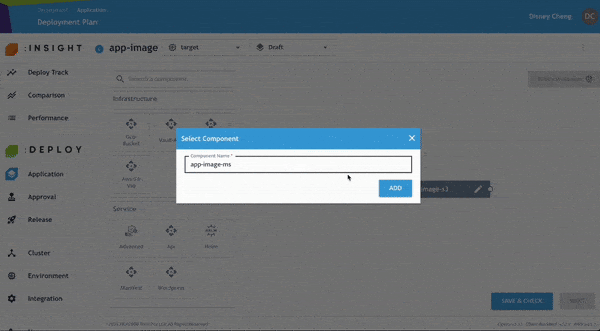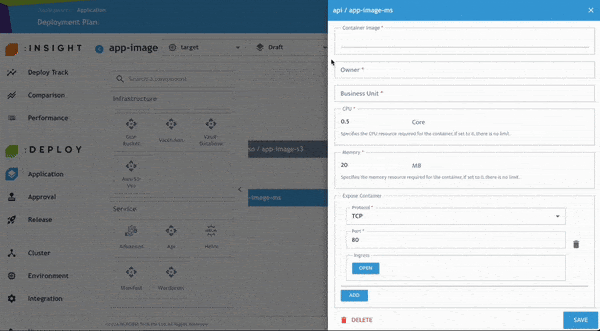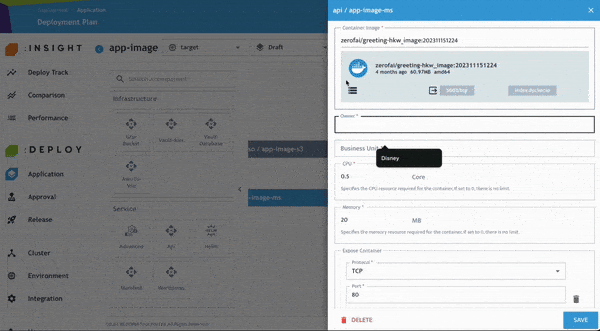
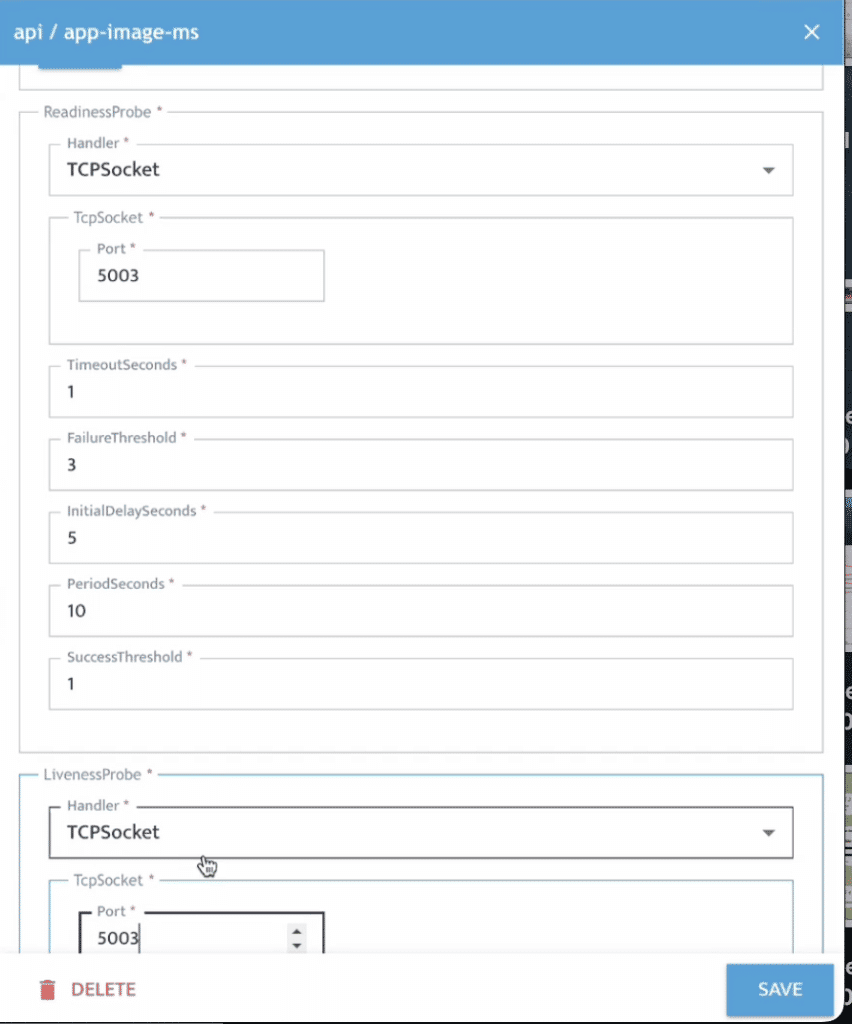
- 輸入相關資訊,例如 Image Name、Exposed Port、Readiness 與 Liveness Probe 等設定。
- 啟用「Secret Managed by Vault Secret Operator」功能。
- 點選 Save。
步驟 4:建立配置流程
由於 API Service 依賴 S3 Bucket,使用者可以透過連接元件方式,快速建立 Provisioning Flow。
- 只需拖曳元件後方的連線即可完成關聯。
- 接著選擇「Save & Check」。
此時,DEPLOY 將透過內建 Policy Check Engine 驗證部署設定。結果會如下顯示:
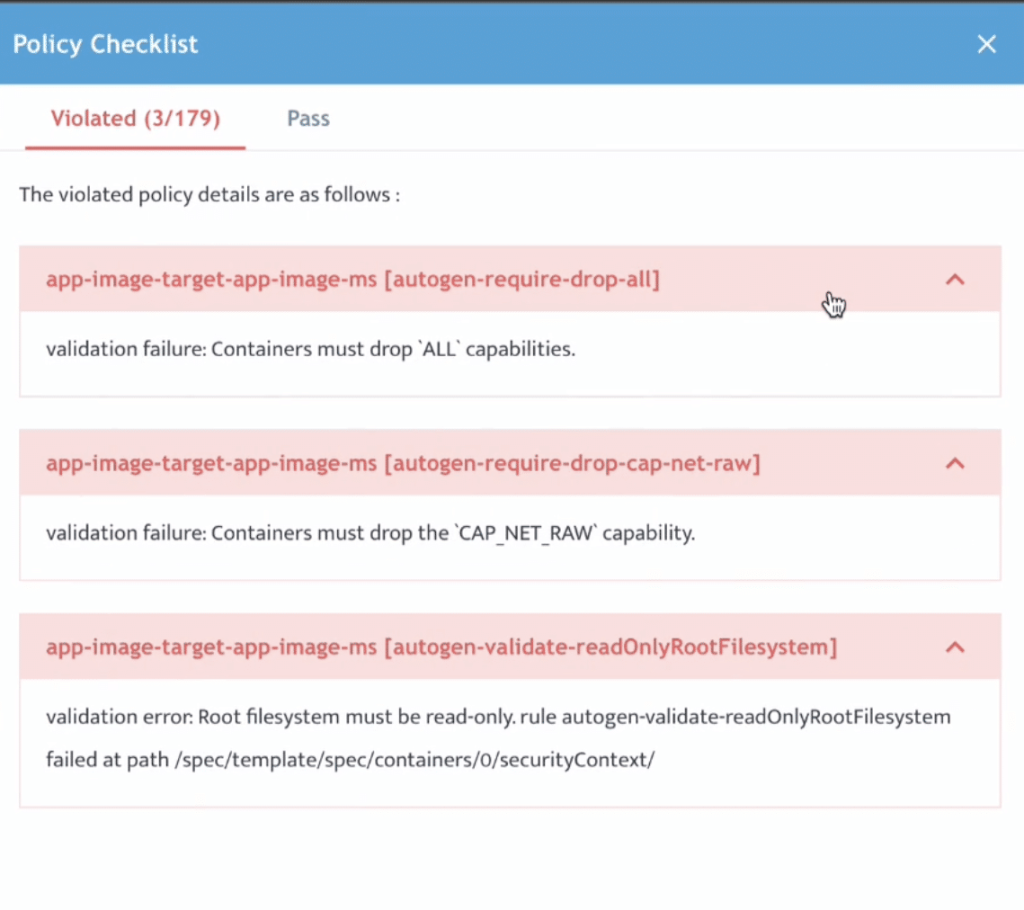 開發人員可進一步檢查並修正任何 Policy Violation,以符合企業內部與產業治理要求。之後即可提交 Application。
開發人員可進一步檢查並修正任何 Policy Violation,以符合企業內部與產業治理要求。之後即可提交 Application。
第 5 步:審核與發布
當 Application Profile 提交後,使用者可在 Approval 頁面查看狀態。
- 點選左側面板中的 Approval,目前狀態會顯示為「Pending for Approval」。
- 點選 Violation 可再次檢查 Policy Violation。
- 點選 Notes 可查看開發人員備註。
- 在 Action 中點選 Approve。
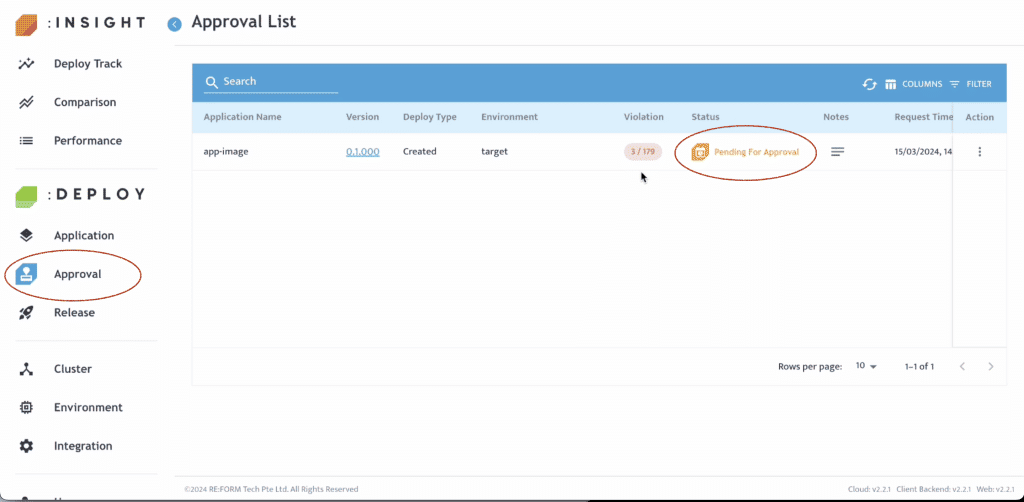
完成核准後,Application 即可進入 Release 階段。許多企業會要求由指定團隊於特定時間執行正式上線。因此,
若要進行部署發布,您可以:
- 點選面板中的「Release」。
- 在 Action 中選擇 Deploy。
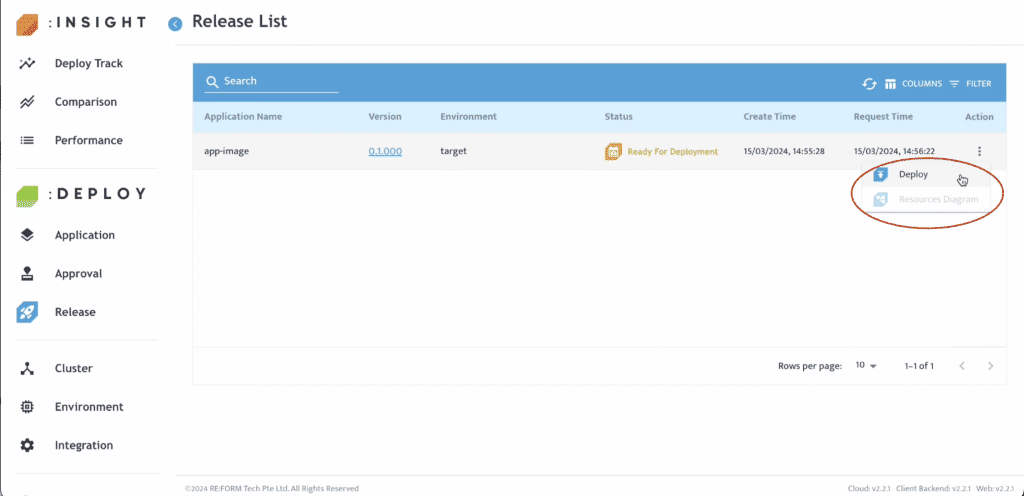
若需建立 UI 元件,可依照上述流程完成部署與發布。
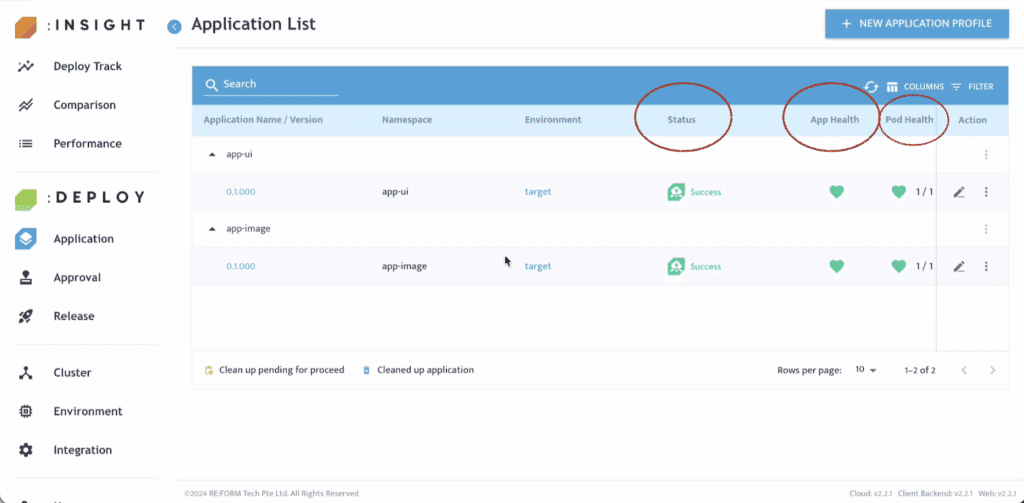
第 6 步:檢視應用程式狀態與 Pod 狀態
當 UI 正在發布時,DNS Registration 與憑證建立可能需要數分鐘完成。待所有程序完成後,可進一步確認 App Health 與 Pod Health 狀態。
恭喜,您已成功部署一個健康的 Web Application。
RE:FORM 協助企業從開發到部署全面優化 DevOps 工作流程與應用交付。透過單一集中式入口,企業可建立標準化應用開發與部署流程,並具備簡易 Drag-and-Drop 基礎架構整合能力,以及可客製化分析報表。
無論您的團隊規模是 20 人或 20,000 人,RE:FORM 都能提供高擴充性且安全的平台工程解決方案,在不增加人力編制的前提下,同時兼顧安全治理與交付效率。依原文敘述,其目標是協助企業大幅提升 DevOps 效率。
立即聯絡我們,了解 RE:FORM DEPLOY 如何協助您的企業在數位轉型時代蓬勃發展。