資訊悅報 Vol.52|RE:FORM REASON: 寫得出長文卻沒處置步驟?破解傳統 AIOps「中看不中用」的自動化困境
部落格來源:How to build Agentic AI? Here’s what most SMEs

寫得出長文卻沒處置步驟?破解傳統 AIOps「中看不中用」的自動化困境
毫無疑問,AI 導入是 2026 年最熱門的議題。令人意外的是,根據研究,亞太地區是 AI 導入率第二高的區域,僅次於北美。
從中國到印尼、從日本到印度,每一間企業的董事會都被告知:
雖然 AIOps 已經證明能對企業損益產生實質影響,但報告指出,仍有 68% 的企業尚未清楚理解 AIOps 解決方案的影響,且許多企業在導入過程中失敗。
依我們建置 AI Agent 與 AIOps 解決方案的經驗,以下是多數組織在建置 agentic AI 時最常犯的錯誤。
為什麼 AIOps 專案會失敗?
以下是我們在建置 AIOps 時最常看到、也最昂貴的 6 個錯誤。
1. 以技術為中心,而不是以問題為中心
許多 AIOps 專案一開始就過度關注 AI 功能與框架編排,卻沒有聚焦在它究竟要解決哪一個具體商業問題。
2. 推理失效
大多數 AI Agent 真的會推理嗎?其實未必。它們更多是在偵測模式與進行比對。
3. 脈絡錯誤
AI 幻覺已是眾所周知的問題。然而在 AIOps 中,其後果不只是內容不準確。Agent 可能變得前後矛盾,經常忘記預先定義的指令、混淆狀態,
4. 分析冗長,卻沒有可執行輸出
許多 AIOps 的輸出是冗長且結構完整的文章。它們可能是準確的,
5. 沒有人工回饋閉環
沒有從人工回饋中學習的 AI Agent,需要持續由人監督,
6. 資料治理薄弱
用不一致的資料訓練 AI Agent,會讓它繼承資料基礎中的偏差與缺口。
「深度推理」實際上代表什麼?
Agentic AI 中的深度推理,代表一件具體的事:它能拆解問題、
能夠實現這類推理的架構方法稱為「思維樹(ToT,Tree of Thoughts)」推理。它不是產生單一線性的回答,
其實務效益相當明確,例如:
- 系統會在提交前對輸出結果進行驗證,降低錯誤。
- 平均修復時間(MTTR)顯著下降。
- 推理過程軌跡可以被檢視、挑戰與修正。
- 準確度會透過自我改善回饋閉環隨時間提升。
如何建置 AI Agent 與 AIOps:6 件必須做對的事
從一個高頻率且會造成損失的的事件類型開始
聚焦式 AIOps 的競爭優勢,在於解決具體的商業問題。要建置真正可用的 AIOps,應先找出最常發生、最消耗工程資源,
結構化推理:思考、假設、驗證、修正、記錄
若要充分發揮 AI Agent 的價值,就必須設計完整的推理迴路:系統應能形成假設、
脈絡補強
每一個事件都提供有用訊號:先前告警、過往修復方式、組態變更、
可行動輸出
在建置模型前,應先思考輸出格式應該長什麼樣子。
回饋閉環:可被教導,也可被修正
工程師所做的每一次修正,都是一次訓練機會。
架構獨立性
AI 模型市場變動快速。建置 AIOps 時,若能採用不綁定特定模型的架構,並支援在不同 LLM、雲端與地端 GPU 配置中運行,會是最具未來彈性的做法。
一個真正可用於正式環境的 AI Agent / AIOps:RE REASON
什麼是 REASON?
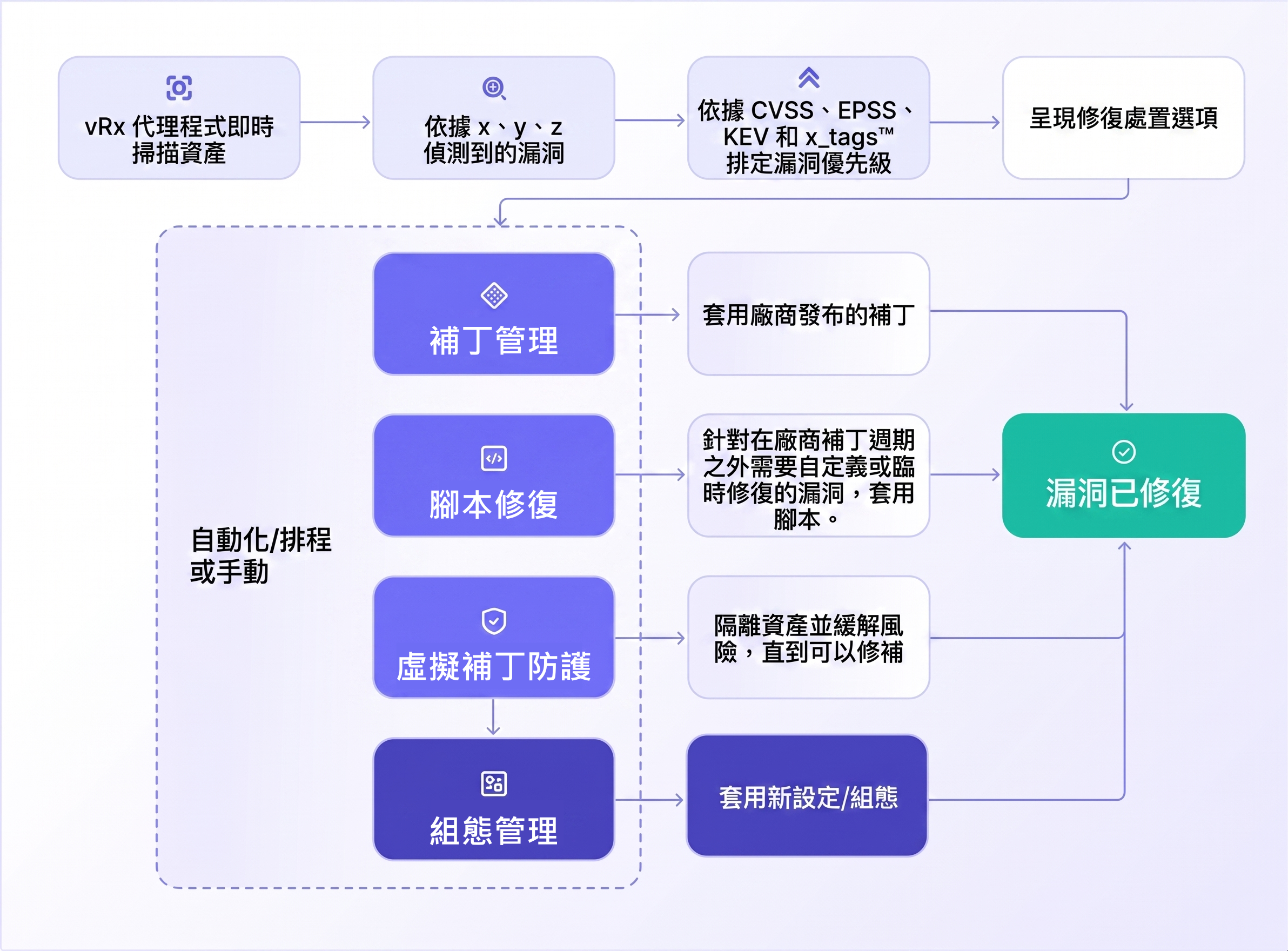
REASON 是一套可地端部署的 AI 深度推理與回應平台,位於既有告警堆疊與 ITSM 工作流程之間。
不同於傳統雲端優先、資料需求龐大且依賴特定平台的 AIOps 工具,REASON 會像企業自己的工程師一樣,逐步思考事件。
無論是處理新情境、不完整資料,或多變因故障,REASON 都能套用深度多步驟推理,並將解法轉化為可行動的修復建議。
REASON 可以做什麼?
- 地端部署:
資料與處置脈絡完整留在企業環境內。適合資料主權是硬性要求的受監管產業。
- 思維樹深度推理:
以多步驟推理將事件拆解為可驗證的假設,交叉驗證證據,並產生結構化結論,即使面對新型、不完整或多變因情境也能處理。 - 告警到工單閉環:
從告警平台接收訊號,執行深度推理,並將可追溯、可稽核且完整的建議直接寫入 ITSM 工作流程。 - LLM 與 GPU 不綁定架構:
可隨 AI 市場演進自由替換語言模型,從最小硬體配置開始,僅在事件量需要時擴充 GPU 能力。各層皆無供應商綁定。 - 人工回饋與自我改善:
將工程師的修正與確認納入回饋閉環。相似事件會逐步變得更快、更一致地被處理。平台也會持續從團隊專業中變得更聰明。 - 透過 MCP、API、A2A 輕量整合:
以受控且具權限邊界的協定,連接既有監控、SIEM 與 ITSM 系統。不需要資料搬移。
REASON 是工程師可信任的協作夥伴,提供一套能記憶、能思考、









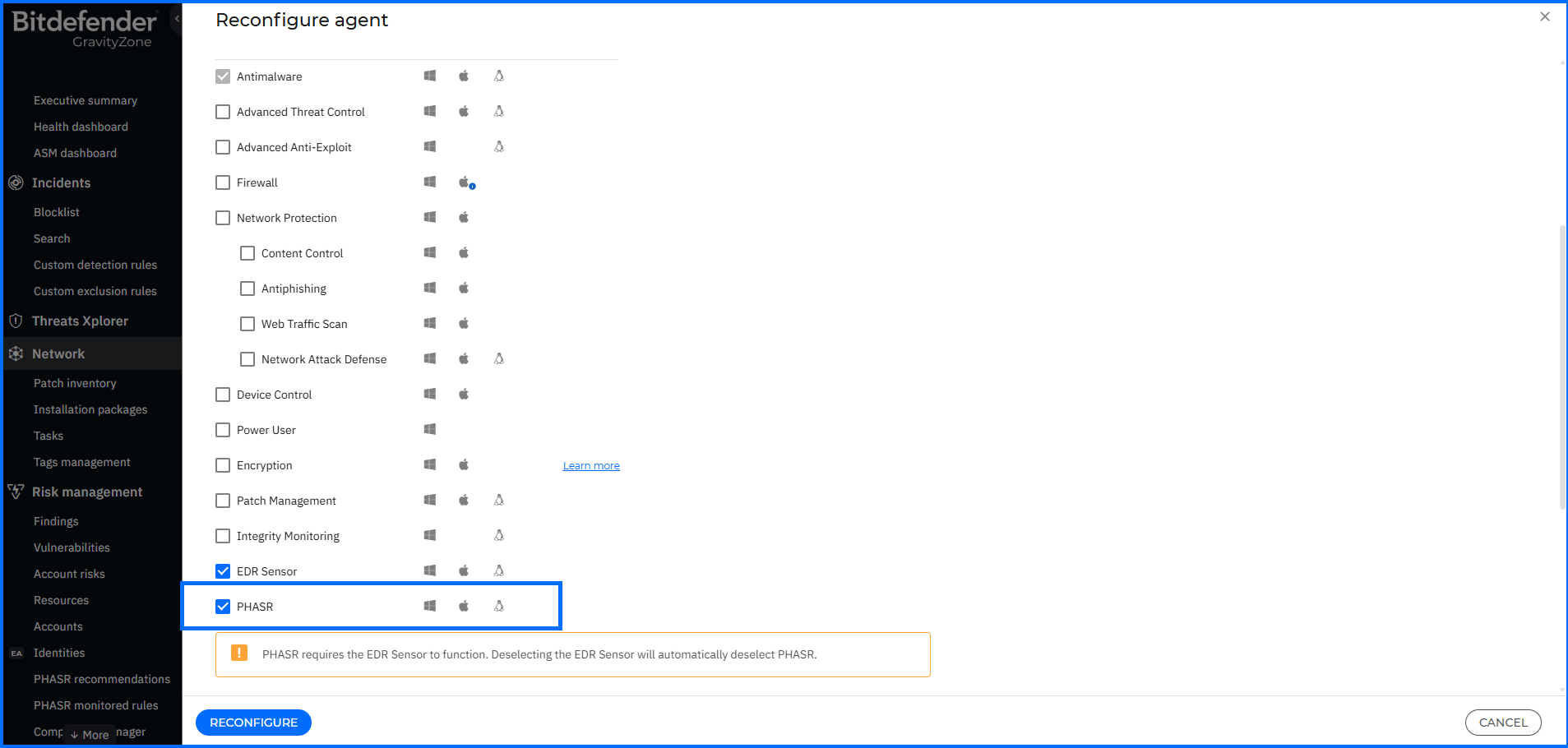
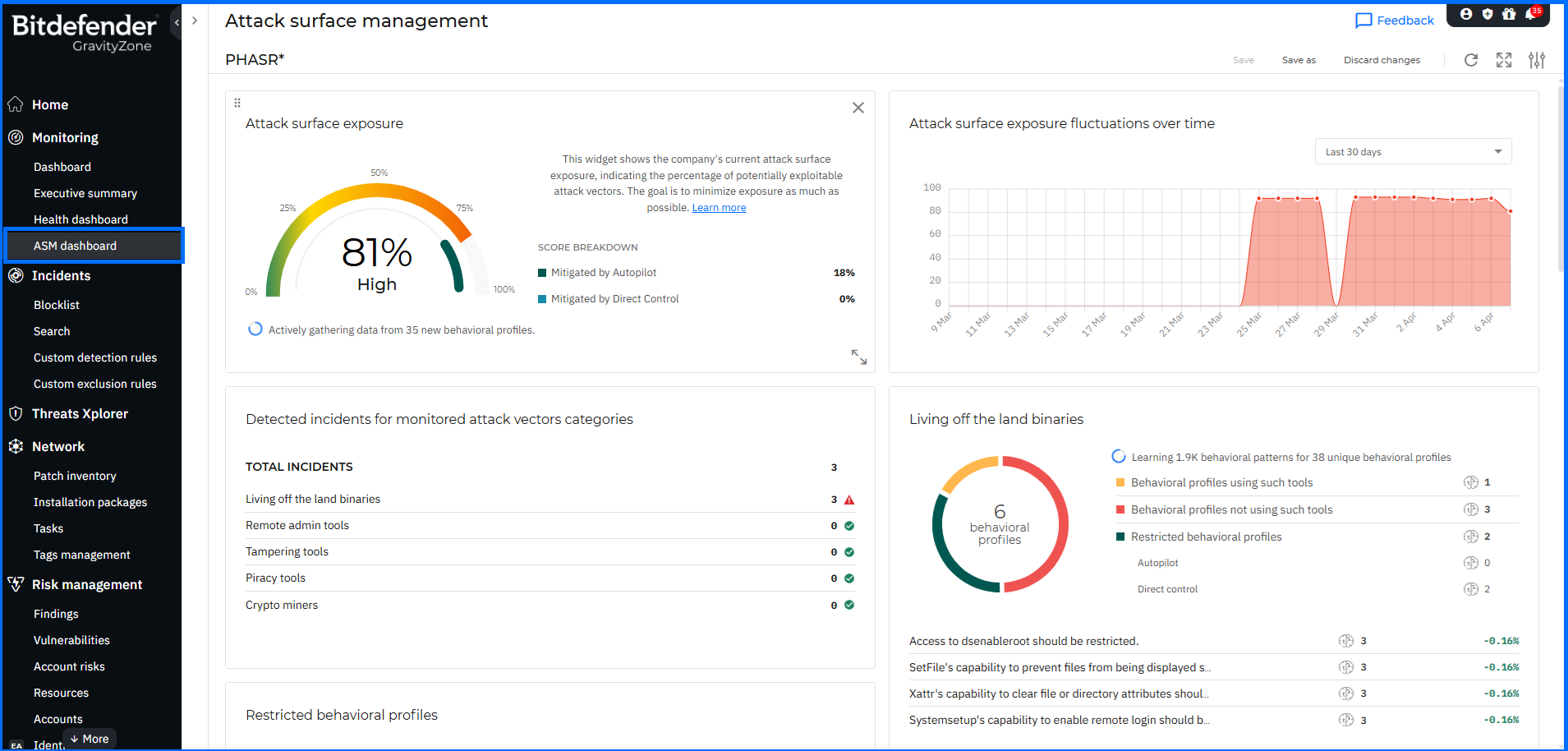
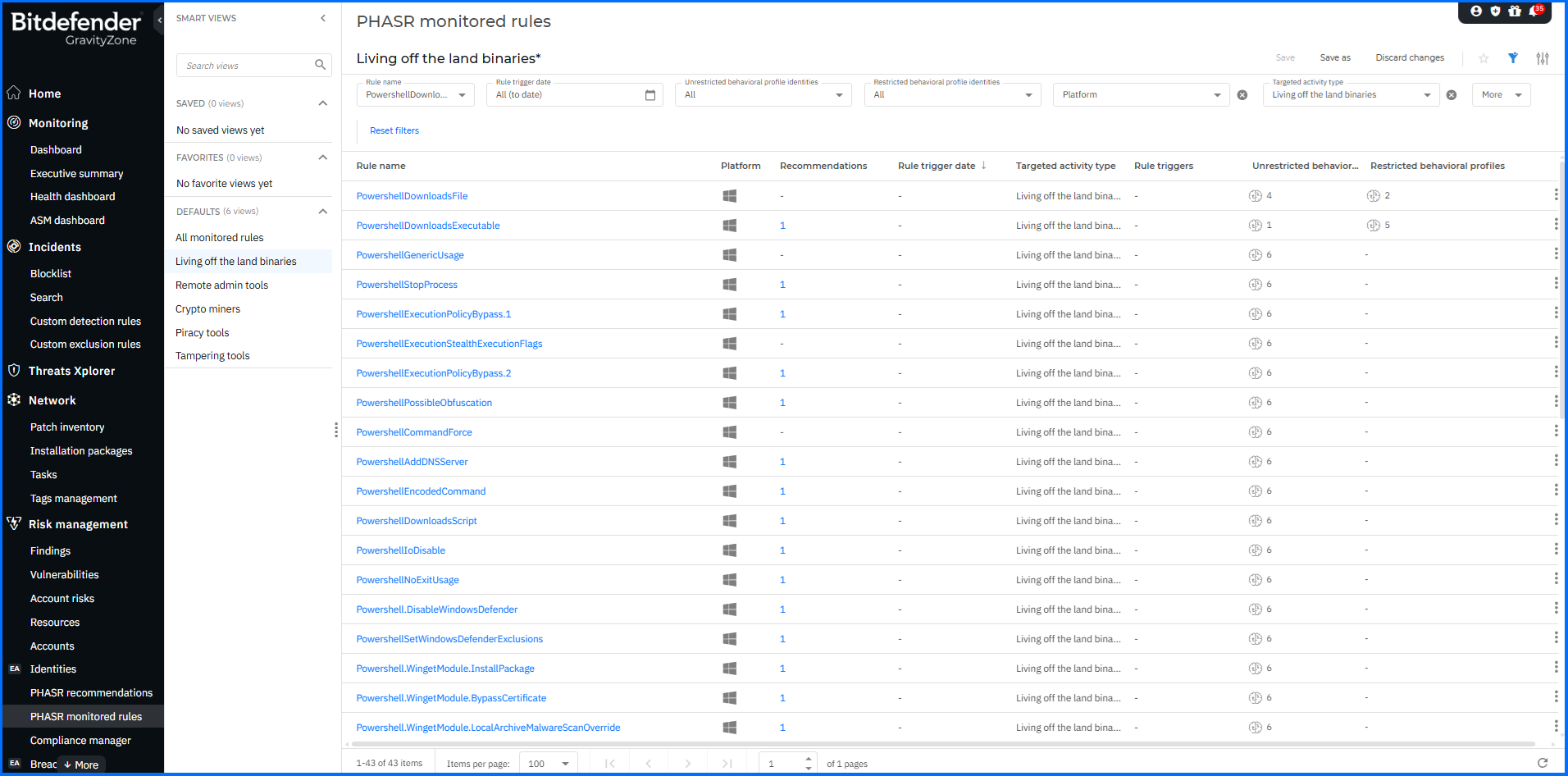
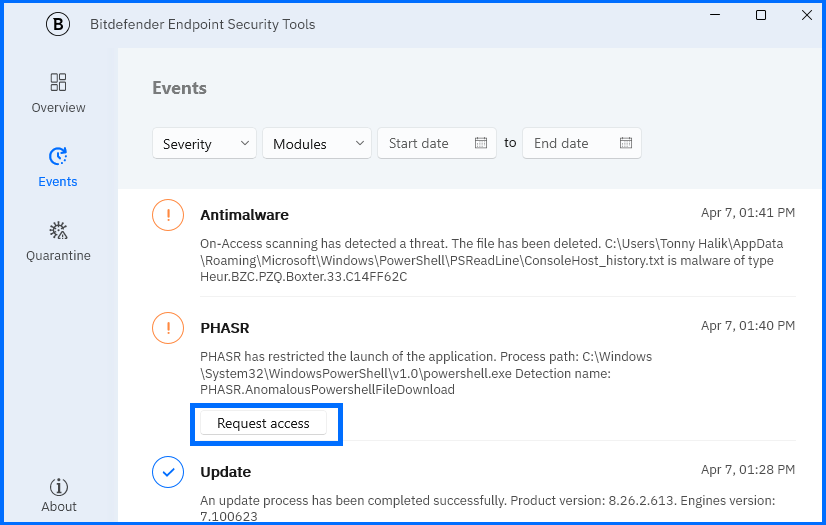





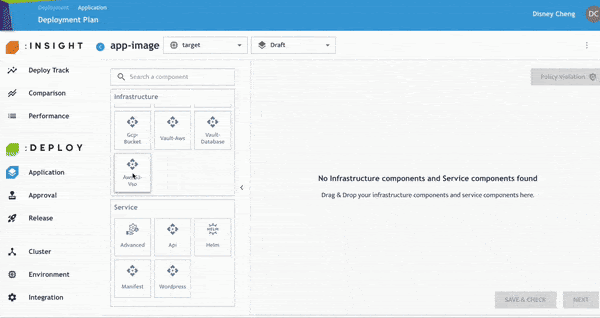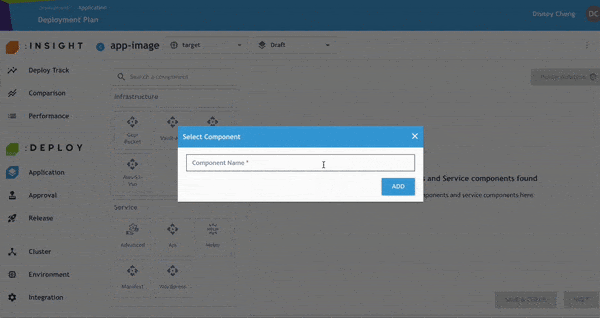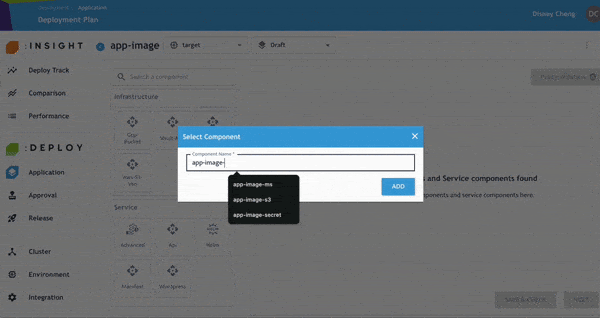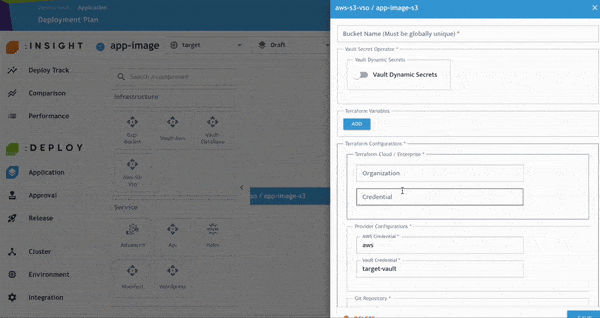

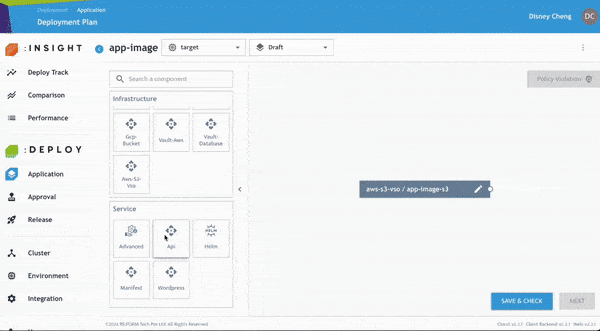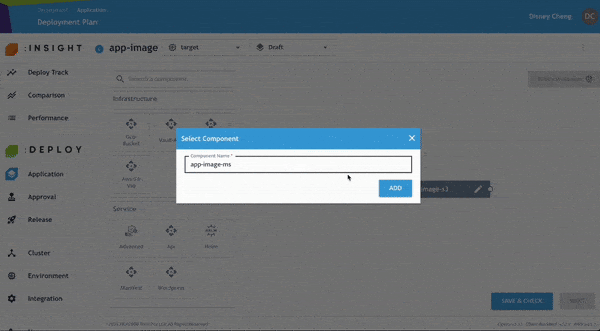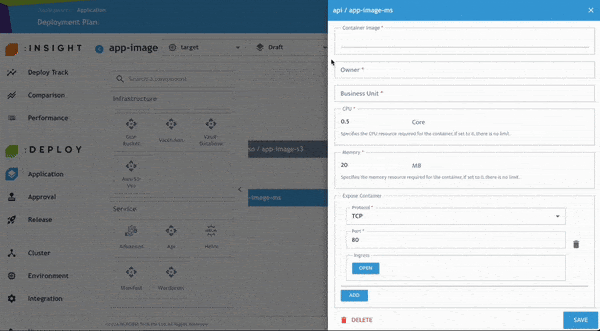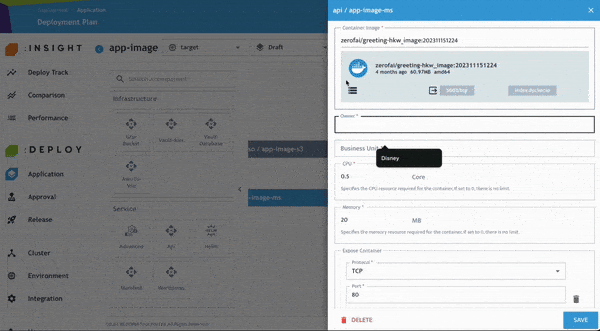
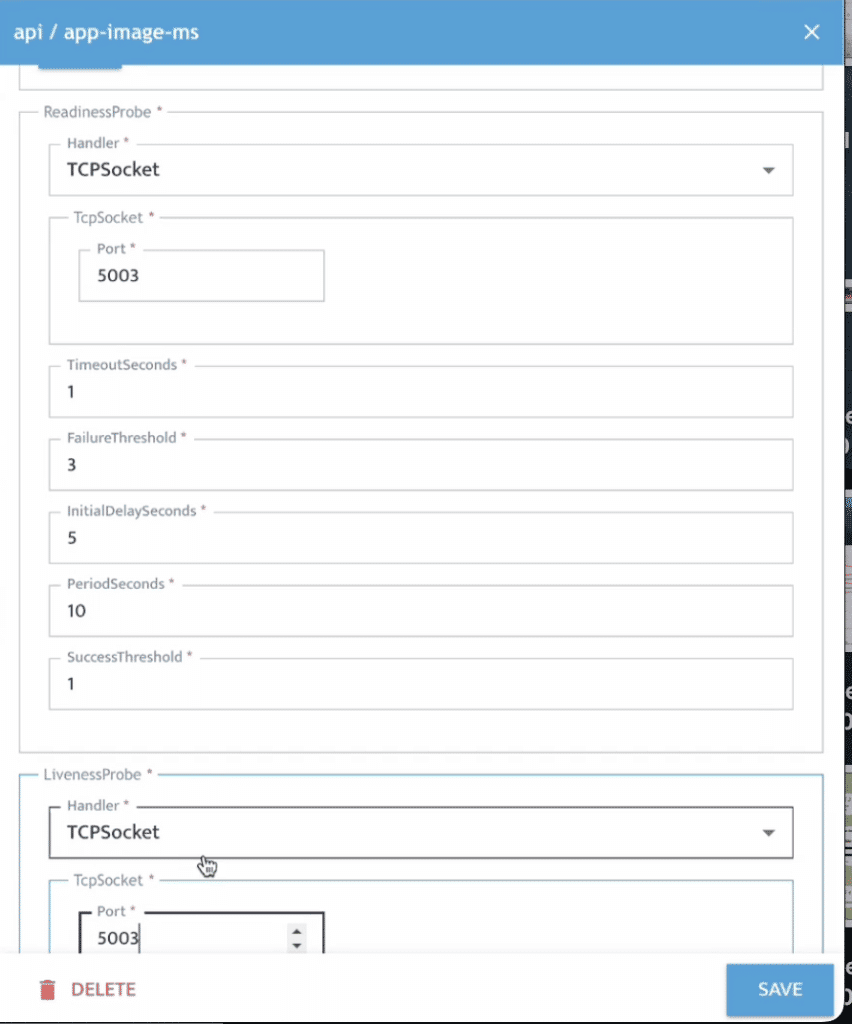
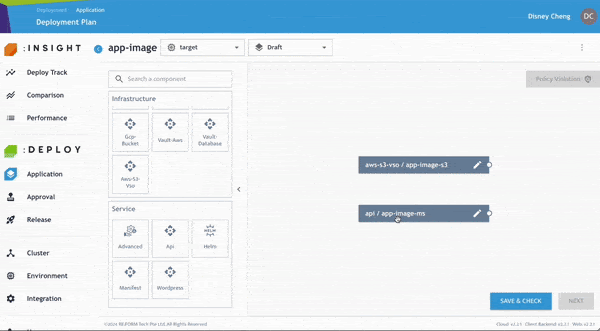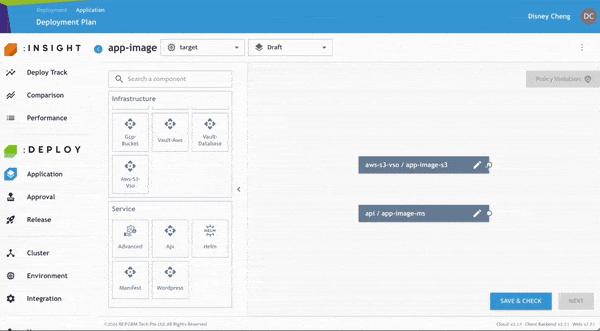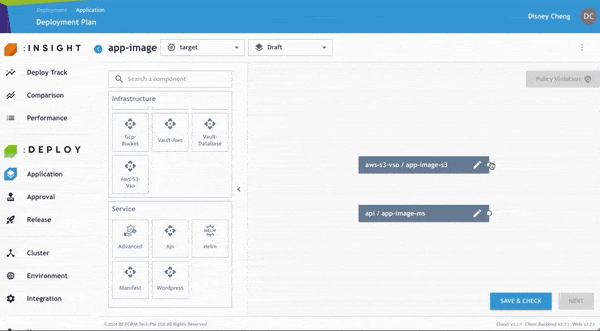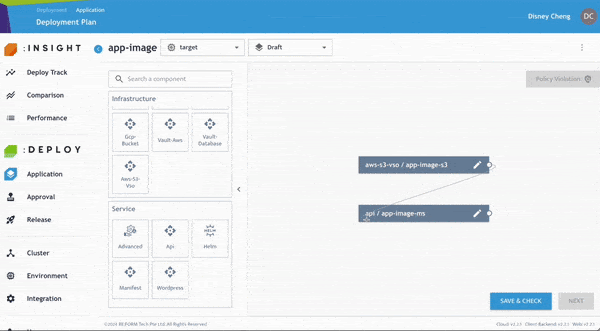
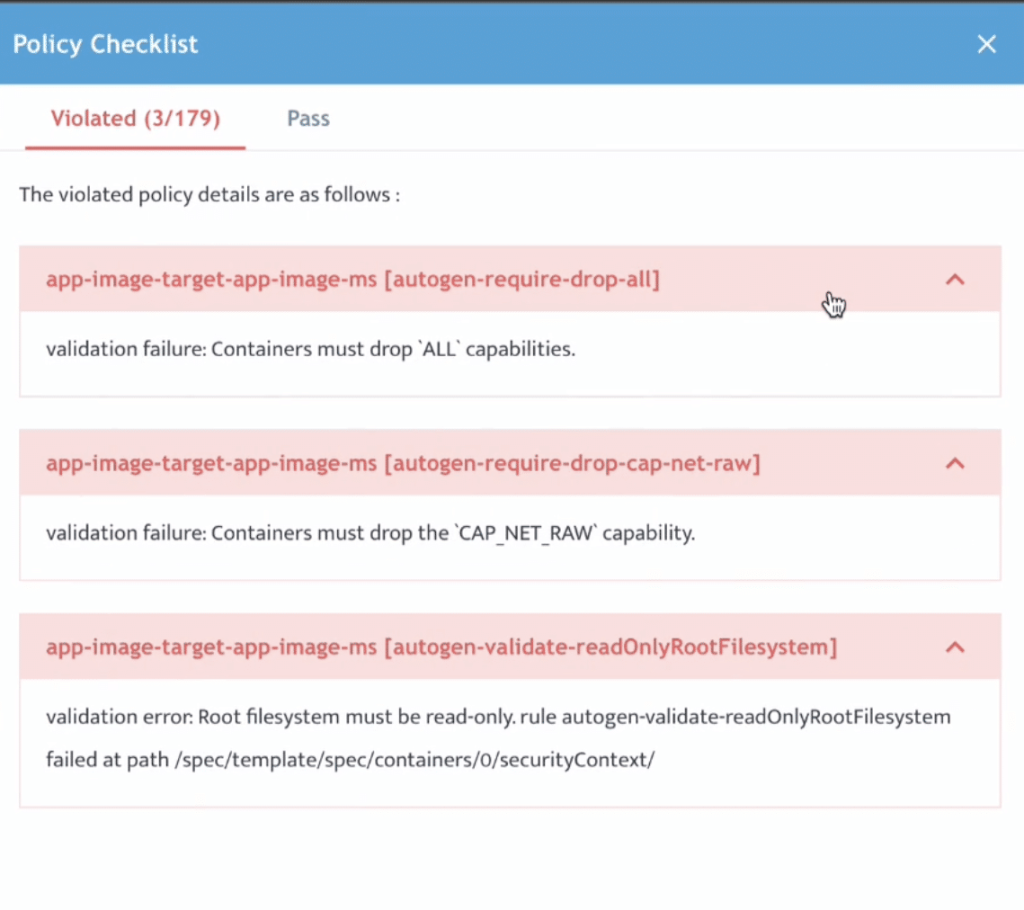 開發人員可進一步檢查並修正任何 Policy Violation,以符合企業內部與產業治理要求。
開發人員可進一步檢查並修正任何 Policy Violation,以符合企業內部與產業治理要求。