資訊悅報 Vol.50|Bitdefender: 如何解決 Linux 雲端伺服器遭 Living off the Land (LOTL) 攻擊?利用 PHASR 進行行為阻斷
部落格來源網址:Introducing Proactive Hardening and Attack Surface Reduction (PHASR) for Linux and macOS


隨著 Linux 成為雲原生基礎架構的主流,而 macOS 也逐漸成為開發團隊與高階主管等高價值目標的標準作業環境,
為了因應這類攻擊面風險,Bitdefender 將其 Proactive Hardening and Attack Surface Reduction(PHASR)技術擴展至 Linux 與 macOS,進一步補強既有的 Windows 強化能力,並整合於 GravityZone 統一安全平台之中。
預防:第一道防線
GravityZone PHASR 作為預防策略的核心基礎層,透過 AI 驅動的行為分析引擎,將資安從被動式偵測轉向主動式強化。
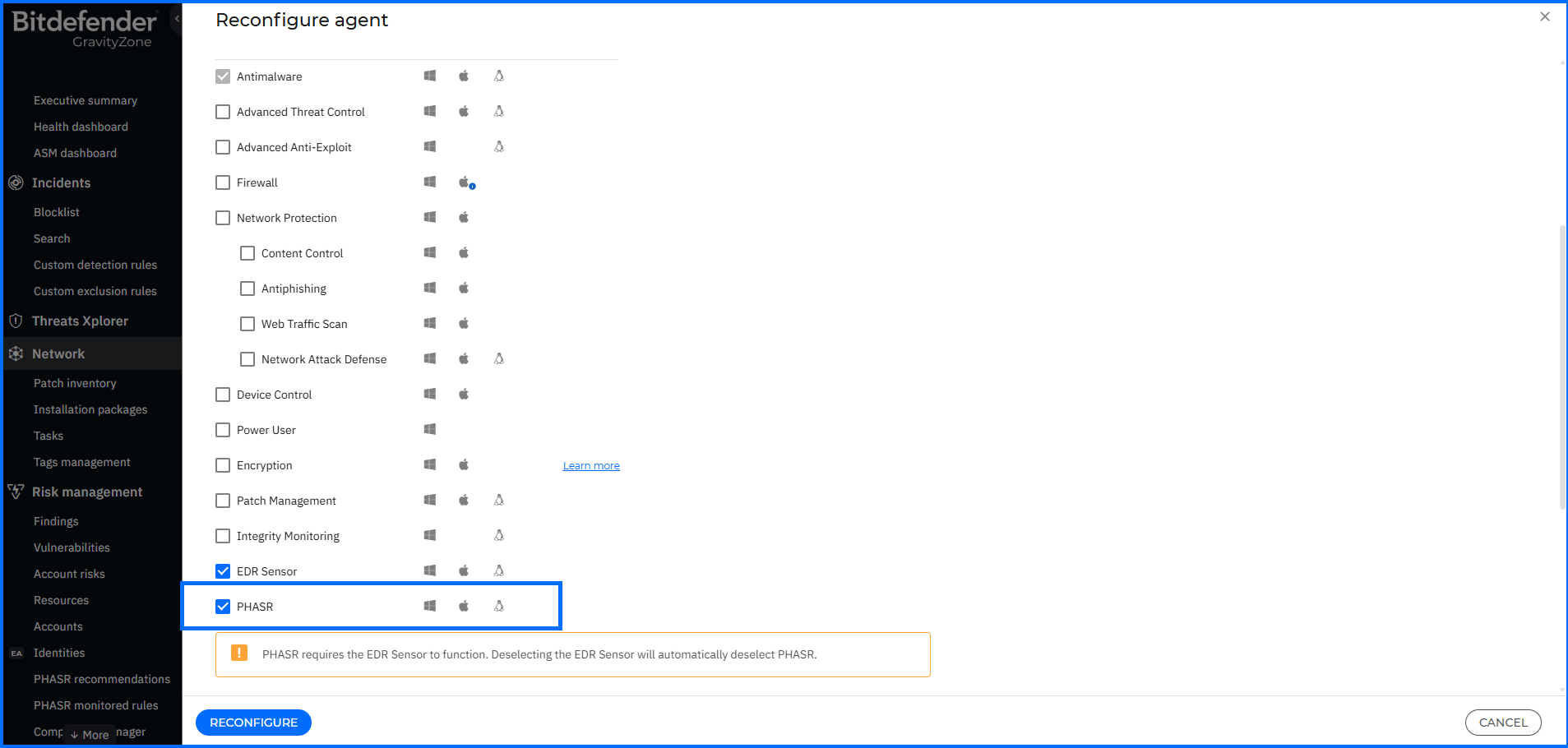
當 PHASR 作為 Bitdefender Endpoint Security Tools(BEST)的一部分部署於完整 GravityZone 架構中時,可在 Windows、macOS 與 Linux 環境提供一致且細緻的防護能力。
不同於「一體適用」的傳統安全模式,PHASR 採用無縫且可調適的防禦機制。
例如,在 Linux 環境中,PHASR 不需要完全停用 shred 工具,而是僅限制其修改檔案權限以取得未授權寫入能力的行為。在 Windows 環境中,則可限制 PowerShell 執行編碼腳本或對外建立網路連線,同時保留其合法管理功能。
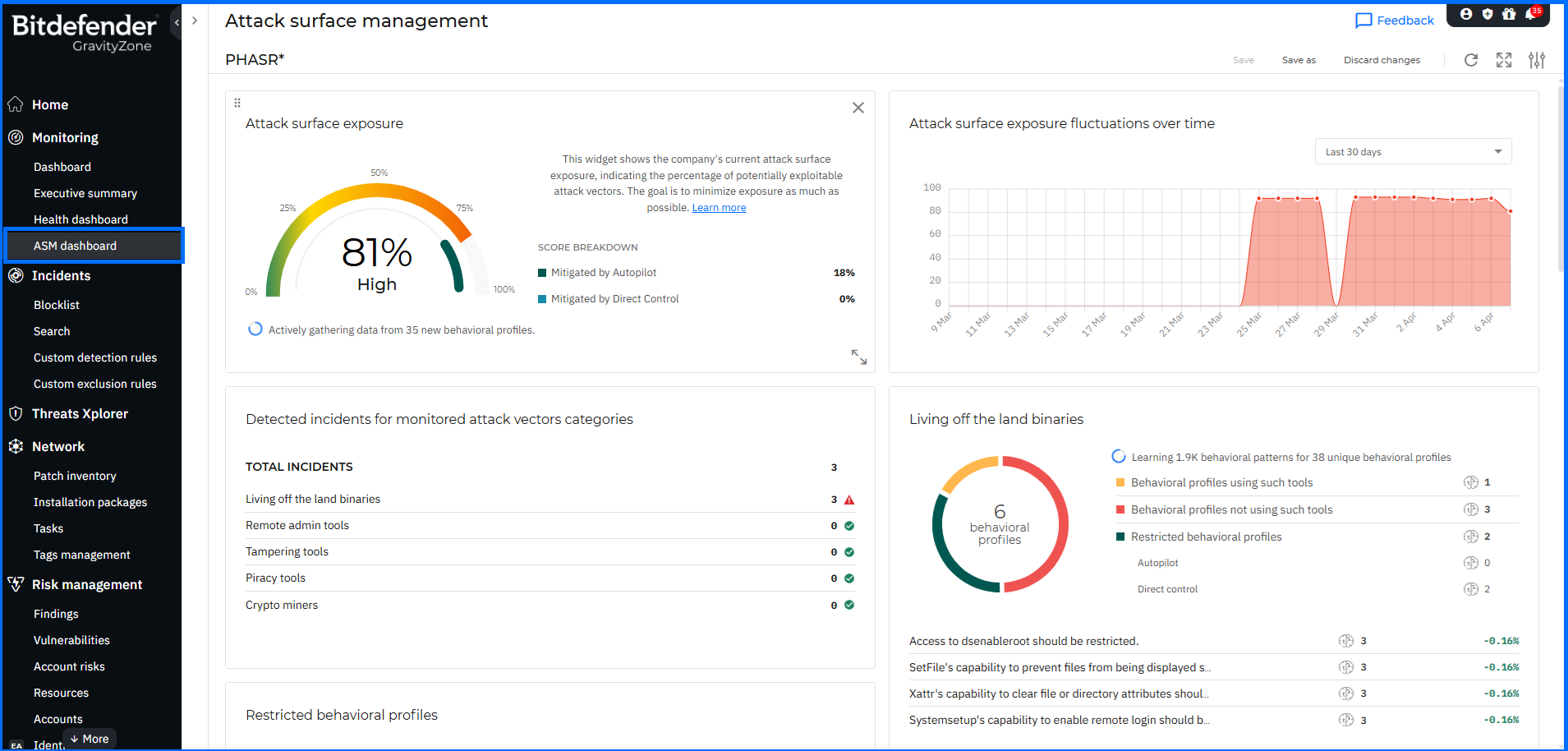
PHASR 提供兩種操作模式,以平衡自動化與管理控制需求:
- 第一種為 Autopilot 模式,透過 AI 行為分析自動管理限制策略。
- 第二種為 Direct Control 模式,提供可執行的建議,由管理員進行細部審核與手動套用。
這使企業能針對以下五類攻擊向量建立客製化防禦策略:
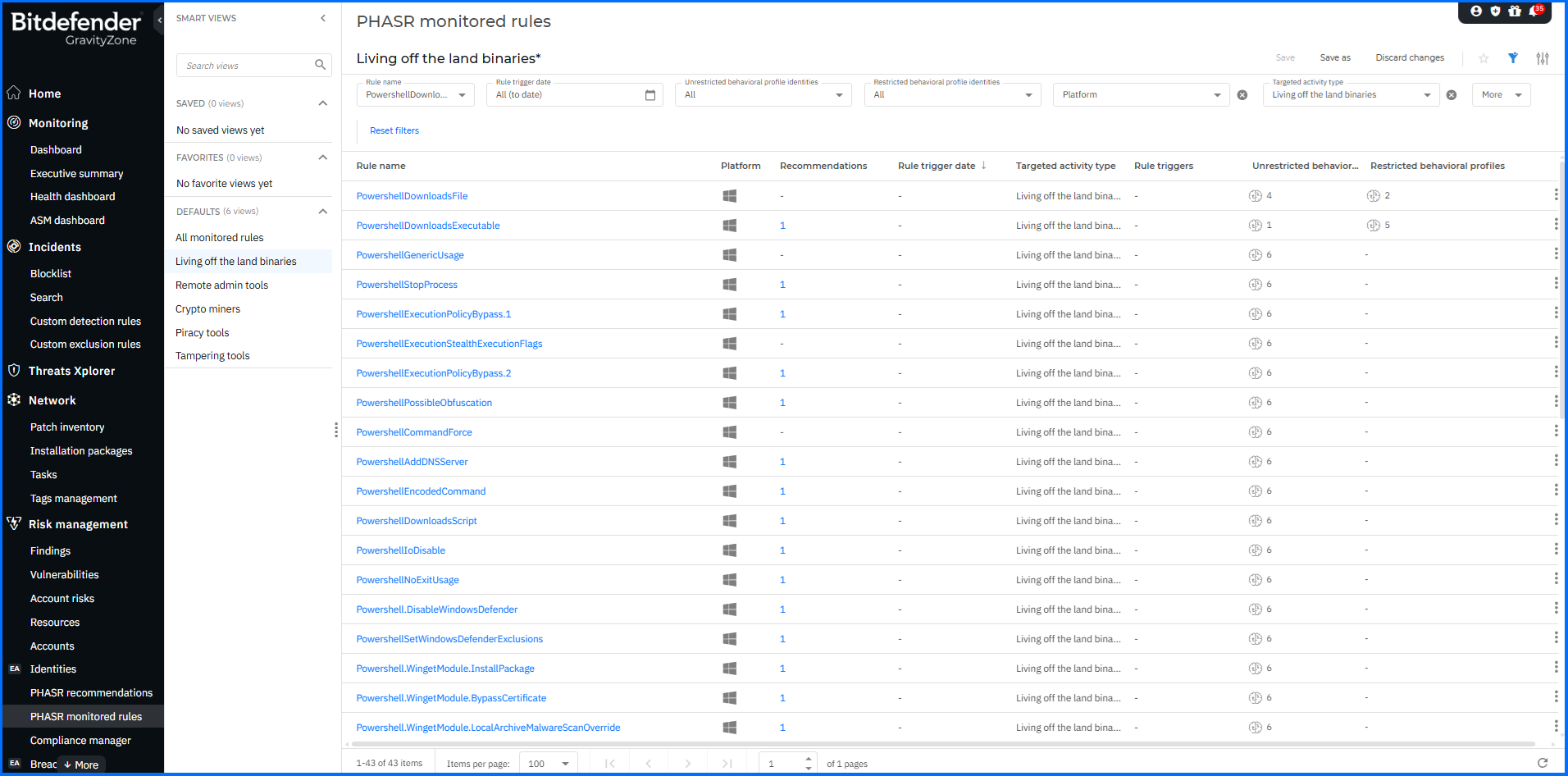
- LOTL 工具
攻擊者濫用系統內建的管理與維運工具,在正常系統活動中隱藏惡意行為。 - 竄改工具
用於修改軟體或繞過安全控制,以停用防禦機制的工具。 - 破解工具
用於繞過軟體授權限制的非法工具。 - 挖礦工具
未經授權的加密貨幣挖礦工具,會占用系統資源並降低效能。 - 遠端管理工具
原本合法的遠端管理工具,遭攻擊者武器化後,用於未授權存取或資料竊取。
即使某項工具或行為已被自動或手動封鎖,PHASR 的 Request Access 功能仍可確保營運不中斷。
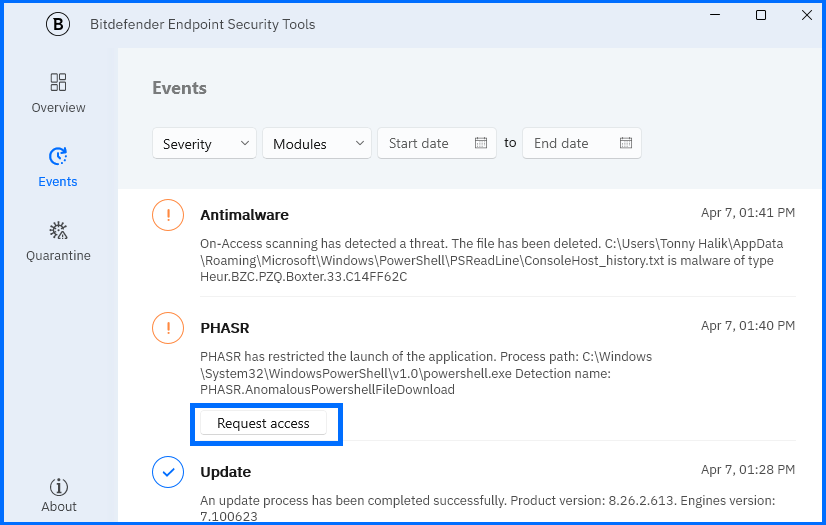
經管理員核准後,PHASR 會開放存取權限,並自動更新行為規則;
PHASR 是怎樣發揮作用以對抗對手的呢?
為了說明 PHASR 的實際防禦效果,以下以 Linux 環境中的典型攻擊情境為例:
為了確保即使初始入口遭封鎖後仍能重新返回系統,
接著,攻擊者可能透過 dnscat2 等 command-and-control(C2)
為了掩蓋痕跡並避免後續鑑識分析,攻擊者還可能濫用 shred 工具覆寫關鍵日誌與鑑識資料,試圖讓調查人員失去可視性。
在雲原生 Linux 環境中,攻擊最終通常會轉向資源變現,例如部署 cpuminer 等挖礦工具,占用 CPU 資源,導致系統效能下降並增加營運成本。
PHASR 能針對此類情境中的每一項工具與具體操作建立限制規則,
更重要的是,PHASR 的限制策略會迫使攻擊者產生更多異常行為,
總結
PHASR 擴展至主流作業系統平台後,進一步強化了企業的預防層能力,
藉由限制 LOTL 工具等高風險合法工具的使用,PHASR 能迫使攻擊者暴露更多異常行為,提高偵測機率。
想了解您的環境目前暴露了哪些風險?Bitdefender 提供免費的內部攻擊面評估,
如需進一步了解 PHASR 與相關效益,深入了解 PHASR 的技術能力與運作原理,歡迎隨時與我們聯繫。






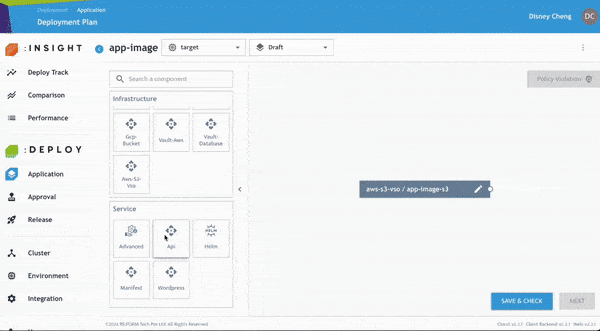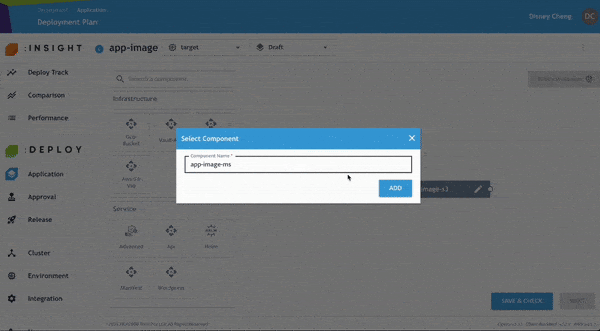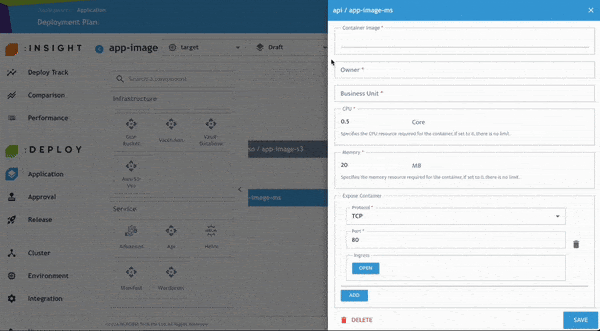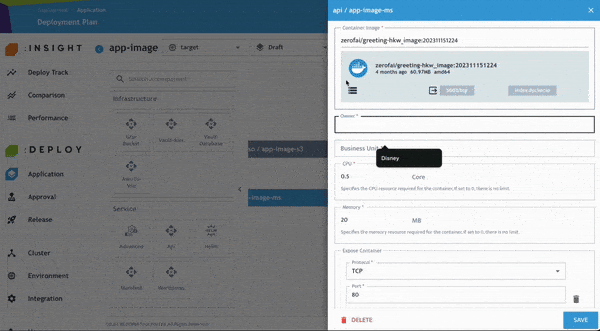
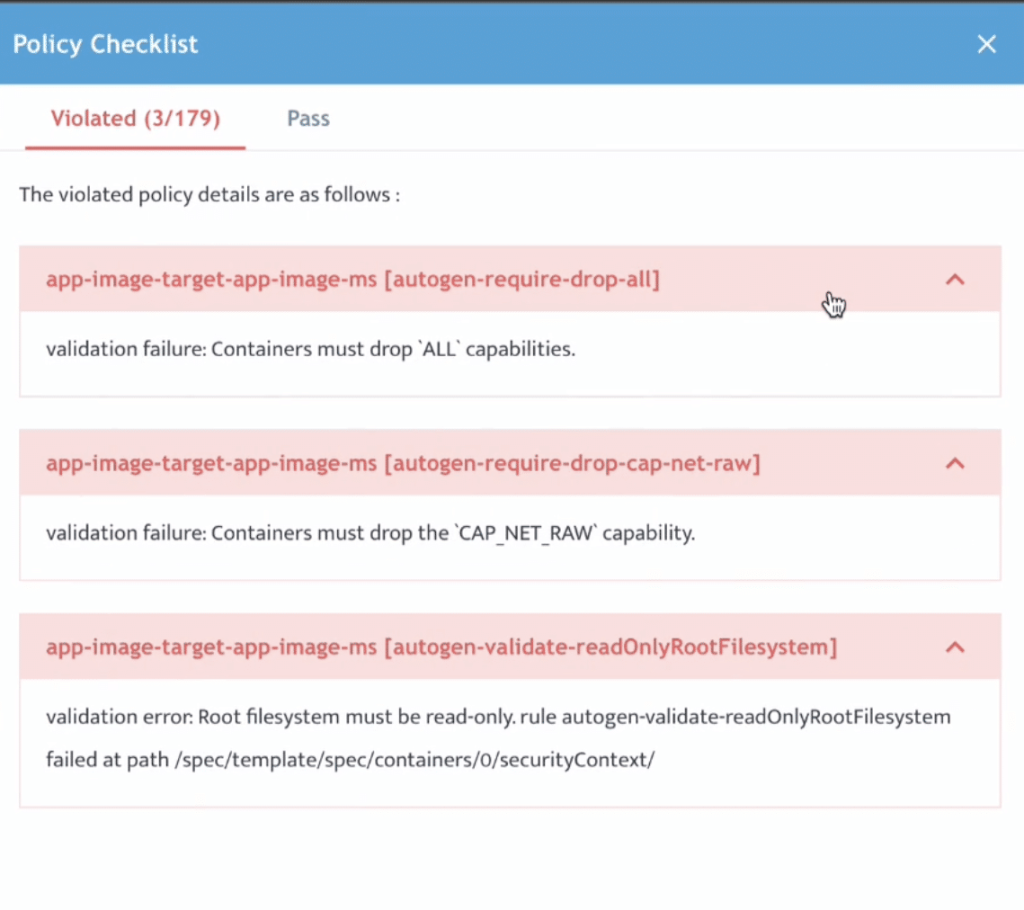 開發人員可進一步檢查並修正任何 Policy Violation,以符合企業內部與產業治理要求。
開發人員可進一步檢查並修正任何 Policy Violation,以符合企業內部與產業治理要求。